728x90
반응형
이번 챕터는 평소 궁금하던 sensor에 대해서 공부할 수 있어서 재미있었어요.
+ TriggerDagRunOperator의 경우 복잡해서 사용안하려고 했는데,
s3 이동 같은 작업은 클래스처럼 정의해서 사용할 수 있다는 이야기를 들어서 유레카였어요

요약
- 센서 : 특정 조건을 센서에 만족하도록 대기하기
- 트리거 : 서로 다른 DAG의 태스크간 의존성 설정하기
- CLI/API : REST API 를 통해 워크 플로 실행하기
- 마무리
설명
1. 센서 : 특정 조건을 센서에 만족하도록 대기하기
로그를 당겨오거나, 작업이 언제 끝날지 기다리거나, hive 테이블에 파티션이 있는지 확인하는 작업에 활용 할 수 있어요
Sensor
- 특정 조건이 참인지 여부를 지속적으로 확인(polling)하는 특수 유형 오퍼레이터
필요한 이유
- 비정규적인 작업을 기다리기에는 비효율적
- 언제 끝날지 모르는 작업을 계속 기다릴 수는 없음
포크(poke)
- 파일이 존재하는지 확인하고 있으면 true 반환
sensor 종류
- FileSensor: Waits for a file or folder to land in a filesystem.
- ExternalTaskSensor: Waits for a different DAG or a task in a different DAG to complete for a specific execution date. (Pretty useful that one )
- HivePartitionSensor: Waits for a partition to show up in Hive.
- S3KeySensor: Waits for a key to be present in a S3 bucket.
- SqlSensor: Runs a sql statement repeatedly until a criteria is met.
- DateTimeSensor: Waits until the specified datetime (Useful to add some delay to your DAGs)
- The TimeDeltaSensor: Waits for a timedelta after the task’s execution_date + schedule interval (Looks similar to the previous one no?)
FileSensor
- 파일이 있는지 확인
|
# 포크 : slot을 차지하고 7일도안 기다림
FileSensor (
task_id="wait_for_supermarket_1",
filepath="/data/supermarket1/data.csv"
)
###########
INFO - poking for file 'data/supermarket/data.csv'
INFO - poking for file 'data/supermarket/data.csv'
INFO - poking for file 'data/supermarket/data.csv'
|
PythonSensor
- python 함수로 조건 정의
- glob : 정규 표현식과 비슷
|
def _wait_for_supermarket (supermarket_id):
supermarket_parh=Path("/data/" + supermarket_id)
data_files=supermarket_path.glob("data-*.csv")
success_file=supermarket_path / "_SUCCESS"
return data_files and success_file.exists
PythonSensor(
task_id="wait_for_supermarkey_1",
python_callable="_wait_for_supermarket",
op_kwargs={"supermarket_id":"supermarket1"},
dag=dag
)
|
SensorDeadlock
- 최대 task 한계에 도달하면 실행이 정지됨
- 해결책
- rescheduler : 대기할 때 슬롯을 가지고 있지 않음
|
# rescheduler (포크 말고 다른거)
waiting_for_file = FileSensor(
task_id='waiting_for_file',
poke_interval=120,
timeout=60 * 30,
mode="reschedule" #default는 Rescheduler
)
---
# timeout 되었을 때 액션도 명시 가능
def _failure_callback(context):
if isinstance(context['exception'], AirflowSensorTimeout):
print(context)
print("Sensor timed out")
with DAG(...) as dag:
waiting_for_file = FileSensor(
task_id='waiting_for_file',
poke_interval=120,
timeout=10,
mode="reschedule",
on_failure_callback=_failure_callback
)
|
2. 트리거 : 서로 다른 DAG의 태스크간 의존성 설정하기
사용 안하려고 했는데, 가끔 에러나는 s3 대용량 파일 이동 작업 같은 경우 사용하면 좋다는 이야기를 들음!
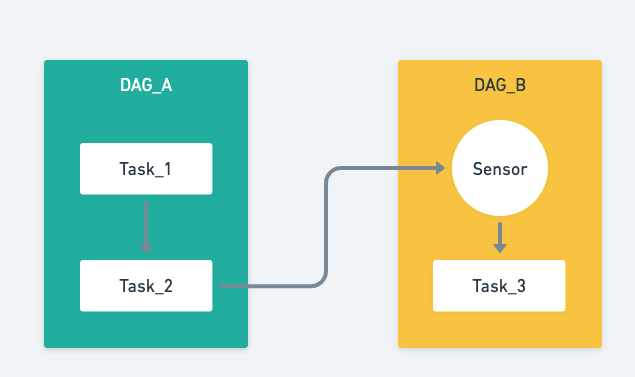
TriggerDagRunOperator
- 호출당하는 쪽은 interval 필요 없음
- tirgger_dag_id로 호출을 함
|
# dag1, 호출하기
TriggerDagRunOperator (
"trigger_task",
trigger_dag_id="create_metric" ##같아야함
)
# dag2, 호출 당하기
DAG (
"create_metric", ##같아야함
start_date= airflow.utils.dates.days_ago(3)
scheduler_interval=None #호출당하는 쪽은 interval이 필요 없음
)
|
ExternalTaskSensor
- 태스크간 의존성을 관리하는데 사용
- external_dag_id 로 호출을 함
부모와 자식의 interval이 다르면 답이없음
책에서는 interval의 차이만큼 execution_delta를 이용해 시간을 조정해주라고 함

udmey 강의에서 들은 marc형은 다른 방식을 추천함
- timout과, reschedule을 적절히 섞는 방법 (난 이게 더 좋은 것 같음)
- 두 dag의 차이만큼을 timeout을 주면, 꼬일 걱정없이 매번 새로운 sensor가 실행되기 때문
- 거기아가 mode=rescheduler로 넣으면 slot도 차지하지 않아서 효율적
타겟
| $ parent_dag.py with DAG ('parent_dag', schedule_interval='10 * * * *'): |
호출
| $ target_dag.py from airflow.sensors.external_task import ExternalTaskSensor from airflow.models import DAG from airflow.operators.bash import BashOperator with DAG ('target_dag', schedule_interval='15 * * * *'): waiting_end_parentd_dag = ExternalTaskSensor( 'waiting_end_parent_dag', external_dag_id='parent_dag', external_task_id='end', timeout=5*60, #5분으로 설정하고 mode='reschedule' #reschedule ) process_ml=BashOperator("process_ml", bash_command="echo 'processing ml'") waiting_end_parentd_dag >> process_ml |
3.CLI/API : REST API 를 통해 워크 플로 실행하기
cli는 테스트할 때 잘 사용안해서 간단히 넘어가고, api는 사용할 일이 있을 것 같아서 테스트 해봄
CLI
사용 예시
- airflow dags trigger -c '{"supermarket":1}' dag1
- airflow dags trigger --conf '{"supermarket":1}' dag1
dag 사용
|
def print_conf(**context):
print(context["dag_run"].conf) # {'supermarket' : 1}
|
API
사용 예시
|
-H "Content-Type: application/json"
-d '{"conf":{"supermarket":1}}'
curl --user "<ID>:<PWD>" -X 'POST' \
'http://<IP>:<PORT>/api/v1/dags/sample_hello_world_dag/dagRuns' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"conf": {},
"dag_run_id": "test-run",
"execution_date": "2021-12-16T02:38:20.364Z"
}'
|
api 설정 켜줘야함 (ex helm)
# bare metal
[api]
#auth_backend = airflow.api.auth.backend.deny_all
auth_backend = airflow.api.auth.backend.basic_auth# helm
config:
api:
#auth_backend: airflow.api.auth.backend.deny_all
auth_backend: airflow.api.auth.backend.basic_auth
마무리
재미난 챕터였음. 이제 다음 챕터인 custom 빌드만 보면 3rd party 코드도 보고 이해할 수 있을 것 같음 ㅎㅎ
Q&A 타임
- sensor는 언제까지 poking 하나?
- 7일 : 60 * 60 * 24 * 7 초
- sensor가 야기할 수 잇는 문제점은 뭘까?
- deadlock이 발생할 수 있음
- concurrency로 인해 slot이 다 차버리면, 정상적으로 실행이 안됨 (대기 시간이 7일인데, @daily면 답 없음)
- TriggerDagRunOperator의 단점
- 학건 : 도저히 관리가 되지 않을 것 같아서 비효율적이지만 하나로 묶었음
sparkSensor 예시
- SparkKubernetesOperator 사용할 때 sensor를 사용했는데, 그 경험 공유
dag 구조는 아래와 같음
- SparkKubernetesOperator
- SparkKubernetesSensor
프로세스틑
- spark job 을 실행하는 operator 가 실행되고 (보통 10초 정도 걸림)
- spark Driver, Executor들이 실행되는데 언제 끝날지 모름
- 그래서 sensor가 바로 실행해서 기다림(poking함)
| from datetime import datetime, timedelta # [START import_module] # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.operators.dummy_operator import DummyOperator from airflow.providers.cncf.kubernetes.operators.spark_kubernetes import SparkKubernetesOperator from airflow.providers.cncf.kubernetes.sensors.spark_kubernetes import SparkKubernetesSensor #etc import pathlib # [END import_module] # [START instantiate_dag] dag = DAG( 'sample-sko-spark', default_args={'max_active_runs': 1}, description='submit spark-pi as sparkApplication on kubernetes', schedule_interval=timedelta(days=1), start_date=datetime(2021, 1, 1), catchup=False, tags=['sample','hgkim'] ) t1 = SparkKubernetesOperator( task_id='task1-spark', namespace="default", application_file=pathlib.Path("/opt/airflow/dags/repo/script/sample/sample-sko-spark.yaml").read_text(), #officially know bug kubernetes_conn_id="kubeConnTest", #ns default in airflow connection UI do_xcom_push=True, dag=dag ) # attach_log (bool) -- determines whether logs for driver pod should be appended to the sensor log l1 = SparkKubernetesSensor( task_id='sample-sko-spark-log', namespace="default", application_name="{{ task_instance.xcom_pull(task_ids='task1-spark')['metadata']['name'] }}", kubernetes_conn_id="kubeConnTest",#ns default in airflow connection UI attach_log=True, # dag=dag, ) t1 >> l1 |
k8s 로그로 설명하면 아래와 같음
| ############################ # Pod ############################ # $ k get pod | grep sko # sample-sko-spark-20220515t012827-1-5bd3597d54b5a9d4-exec-1 1/1 Running 0 14s # sample-sko-spark-20220515t012827-1-5bd3597d54b5a9d4-exec-2 1/1 Running 0 14s # sample-sko-spark-20220515t012827-1-5bd3597d54b5a9d4-exec-3 1/1 Running 0 14s # sample-sko-spark-20220515t012827-1-driver 1/1 Running 0 26s ############################ # logs ############################ # saving log from executors # $ k get pod -n airflow | grep log # sampleskosparksampleskosparklog.7d21881b74bd4c3180d8a470ff4257a5 1/1 Running 0 42s |
SparkKubernetesOperator의 로그
- sparkapplication(CRD)에 단순히 파라미터 전달만함
*** Reading remote log from s3://hgkim/airflow/logs/sample-sko-spark/l1/2022-05-15T19:00:00+00:00/1.log.
[2022-05-16 19:00:17,003] {taskinstance.py:903} INFO - Dependencies all met for <TaskInstance: sample-sko-spark.l1 2022-05-15T19:00:00+00:00 [queued]>
[2022-05-16 19:00:17,021] {taskinstance.py:903} INFO - Dependencies all met for <TaskInstance: sample-sko-sparkl1 2022-05-15T19:00:00+00:00 [queued]>
[2022-05-16 19:00:17,021] {taskinstance.py:1095} INFO -
--------------------------------------------------------------------------------
[2022-05-16 19:00:17,021] {taskinstance.py:1096} INFO - Starting attempt 1 of 1
[2022-05-16 19:00:17,021] {taskinstance.py:1097} INFO -
--------------------------------------------------------------------------------
[2022-05-16 19:00:17,035] {taskinstance.py:1115} INFO - Executing <Task(SparkKubernetesSensor): l1> on 2022-05-15T19:00:00+00:00
[2022-05-16 19:00:17,038] {standard_task_runner.py:52} INFO - Started process 18 to run task
[2022-05-16 19:00:17,041] {standard_task_runner.py:76} INFO - Running: ['airflow', 'tasks', 'run', 'sample-sko-spark', 'l1', '2022-05-15T19:00:00+00:00', '--job-id', '100168', '--pool', 'default_pool', '--raw', '--subdir', '/opt/airflow/dags/repo/dags/sample-sko-spark.py', '--cfg-path', '/tmp/tmpgo1gm4yp', '--error-file', '/tmp/tmplfou7ybs']
[2022-05-16 19:00:17,042] {standard_task_runner.py:77} INFO - Job 100168: Subtask l1
[2022-05-16 19:00:17,090] {logging_mixin.py:109} INFO - Running <TaskInstance:sample-sko-sparkl1 2022-05-15T19:00:00+00:00 [running]> on host sampleskosparkl1.d2684aecb1614d7c84c3d0934954ad06SparkKubernetesSensor의 로그
- 계속 poking 하다가 driver에 있는 로그를 append함
[2022-05-16 19:00:17,152] {logging_mixin.py:109} WARNING - /home/airflow/.local/lib/python3.6/site-packages/airflow/configuration.py:341 DeprecationWarning: The remote_logging option in [core] has been moved to the remote_logging option in [logging] - the old setting has been used, but please update your config.
[2022-05-16 19:00:17,153] {logging_mixin.py:109} WARNING - /home/airflow/.local/lib/python3.6/site-packages/airflow/configuration.py:341 DeprecationWarning: The remote_log_conn_id option in [core] has been moved to the remote_log_conn_id option in [logging] - the old setting has been used, but please update your config.
[2022-05-16 19:00:17,154] {logging_mixin.py:109} WARNING - /home/airflow/.local/lib/python3.6/site-packages/airflow/configuration.py:341 DeprecationWarning: The remote_base_log_folder option in [core] has been moved to the remote_base_log_folder option in [logging] - the old setting has been used, but please update your config.
[2022-05-16 19:00:17,179] {taskinstance.py:1254} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_OWNER=hgkim
AIRFLOW_CTX_DAG_ID=sample-sko-spark
AIRFLOW_CTX_TASK_ID=l1
AIRFLOW_CTX_EXECUTION_DATE=2022-05-15T19:00:00+00:00
AIRFLOW_CTX_DAG_RUN_ID=scheduled__2022-05-15T19:00:00+00:00
[2022-05-16 19:00:17,179] {spark_kubernetes.py:101} INFO - Poking: sample-sko-spark-20220515t190000-1
[2022-05-16 19:00:17,202] {spark_kubernetes.py:121} INFO - Spark application is still in state: RUNNING
[2022-05-16 19:01:17,262] {spark_kubernetes.py:101} INFO - Poking: sample-sko-spark-20220515t190000-1
[2022-05-16 19:01:17,269] {spark_kubernetes.py:121} INFO - Spark application is still in state: RUNNING
[2022-05-16 19:02:17,330] {spark_kubernetes.py:101} INFO - Poking: sample-sko-spark-20220515t190000-1
[2022-05-16 19:02:17,336] {spark_kubernetes.py:121} INFO - Spark application is still in state: RUNNING
[2022-05-16 19:03:17,374] {spark_kubernetes.py:101} INFO - Poking: sample-sko-spark--20220515t190000-1
[2022-05-16 19:03:17,379] {spark_kubernetes.py:121} INFO - Spark application is still in state: RUNNING
[2022-05-16 19:04:17,409] {spark_kubernetes.py:101} INFO - Poking: sample-sko-spark-20220515t190000-1
[2022-05-16 19:04:17,430] {spark_kubernetes.py:90} INFO - ++ id -u
+ myuid=0
++ id -g
+ mygid=0
+ set +e
++ getent passwd 0
+ uidentry=root:x:0:0:root:/root:/bin/bash
+ set -e
+ '[' -z root:x:0:0:root:/root:/bin/bash ']'
+ SPARK_CLASSPATH=':/opt/spark/jars/*'
+ env
+ grep SPARK_JAVA_OPT_
+ sort -t_ -k4 -n
+ sed 's/[^=]*=\(.*\)/\1/g'
+ readarray -t SPARK_EXECUTOR_JAVA_OPTS
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z ']'
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z x ']'
+ SPARK_CLASSPATH='/opt/spark/conf::/opt/spark/jars/*'
+ case "$1" in
+ shift 1
+ CMD=("$SPARK_HOME/bin/spark-submit" --conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS" --deploy-mode client "$@")
+ exec /usr/bin/tini -s -- /opt/spark/bin/spark-submit --conf spark.driver.bindAddress=10.***.1.59 --deploy-mode client --properties-file /opt/spark/conf/spark.properties --class org.apache.spark.deploy.PythonRunner local:///app/main.py
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.0.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
22/05/17 04:00:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/05/17 04:00:45 INFO SparkContext: Running Spark version 3.2.0
22/05/17 04:00:45 WARN SparkConf: Note that spark.local.dir will be overridden by the value set by the cluster manager (via SPARK_LOCAL_DIRS in mesos/standalone/kubernetes and LOCAL_DIRS in YARN).
22/05/17 04:00:45 INFO ResourceUtils: ==============================================================
22/05/17 04:00:45 INFO ResourceUtils: No custom resources configured for spark.driver.
22/05/17 04:00:45 INFO ResourceUtils: ==============================================================
22/05/17 04:00:45 INFO SparkContext: Submitted application: Hgkim-sample-sko
22/05/17 04:00:45 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 3, script: , vendor: , memory -> name: memory, amount: 16384, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
22/05/17 04:00:45 INFO ResourceProfile: Limiting resource is cpus at 3 tasks per executor
22/05/17 04:00:45 INFO ResourceProfileManager: Added ResourceProfile id: 0
22/05/17 04:00:45 INFO SecurityManager: Changing view acls to: root
22/05/17 04:00:45 INFO SecurityManager: Changing modify acls to: root
22/05/17 04:00:45 INFO SecurityManager: Changing view acls groups to:
22/05/17 04:00:45 INFO SecurityManager: Changing modify acls groups to:
22/05/17 04:00:45 INFO SecurityManager: SecurityManager: authentication disabled; u가끔 sensor가 죽는 외부에서 죽는 경우가 있는데 그거는 지금 테스트 중
- schedule_after_task_execution : false 로 변경하면 되지 않을까 추측 중...
참고
- https://marclamberti.com/blog/airflow-sensors/
- https://tommybebe.github.io/2020/11/30/airflow-external-task-sensor/
- https://airflow.apache.org/docs/apache-airflow/stable/security/api.html
- https://mightytedkim.tistory.com/45
- https://mightytedkim.tistory.com/43?category=964180
- https://engineering.linecorp.com/ko/blog/data-engineering-with-airflow-k8s-2/
스터디
- https://www.slipp.net/wiki/pages/viewpage.action?pageId=3276808651040
728x90
반응형
'Data > Airflow' 카테고리의 다른 글
| Airflow) pod external sigterm으로 죽는 현상_해결못해서 retries함 (0) | 2022.06.02 |
|---|---|
| Airflow) S3CopyObjectOperator 이용해서 copy 하기 (0) | 2022.06.02 |
| Slipp) Airflow2.0 스터디_3주차(4/5장) (0) | 2022.05.15 |
| Airflow) context, kwargs 혼용 실습 (0) | 2022.05.09 |
| Airflow) 2.0부터는 scheduler 는 replica 여러개 설정 추천 (0) | 2022.04.28 |