2년전에 회사에서 동기 스터디하면서 정리했던 내용인데
Mongodb) 개발자가 알면 좋은 Mongodb_동기스터디 발표
rdbms만 하다가, nosql을 공부하니 신세계였어요
2주 전에 동기들 모아놓고, Mongodb를 알려줫어요

P글또 5기(개발자 글쓰기 모임)서 피피티 프드백을 해주셨어요 (너무나 소중한 피드백ㅜ 글또를 시작한 이유죠)


그래서 PPT로 발표한 내용을 좀 더 쉽게 풀어써보려고해요 :)
타겟 : 게으른 개발자 == 동기
1. RDBMS만 익숙한 개발자
2. 누군가 떠먹여줬으면 좋겠는 개발자
3. 그냥 궁금한 개발자
목표 : 겉햝기
CRUD 위주의 철저한 Hello-world

1. mongodb란: 잘 나가는 Nosql
Mongodb는 NoSql DB 중 하나다(잘 나간다)
처음에 DB를 공부하면 보통 Oracle을 배우잖아요
NoSql을 공부할 때도 MongoDb부터 시작하더라고요


가장 중요한 특징은 자유도라고 생각해요 Schemaless라고도 하죠


collection은 오라클의 table과 비슷한 개념이에요 ㅎ 관리를 해야되기 때문에 조건들을 설정할 수 있지만
DDL 없이 바로 Insert하면 Collection이 만들어져요
2. 설치(docker, gui툴)
mongodb, mongo compass
설치 과정도 뺄까하다가, 그래도 세팅은 해야되지 않을까 싶어서
Docker-compose로 구성했어요 ㅎ

설치가 완료되면 CMD에서 되는지 확인했어요

3. CRUD -crud
시작하기 전에 mongo compass 하단의 console을 클릭하면
명령어 자동 완성이 되니, 거기서 하는게 더 좋아요
아래처럼 입력하면 되요ㅎ
CRUD는 딱히 설명할게 없어요. 대충 보고 아 그렇구나



find의 $in 은 oracle에서 `in` 과 같은 친구에요


update의 $set 은 oracle에서 udpate on의 `on` 같은 친구에요
4. 예시 - Import, Aggreation
People
import는 mondb tool을 다운받고, cmd에서 가져올 수 도 있는데요
compass로 import 버튼을 누르고 json 파일을 가져올게요
people.json, place.json 만 사용할게요



- find에서는
param 1 : where 절과 동일
param 2 : 보여줄 필드 설정 (o: 안보임, 1: 보임)
- 특정 array에 있는 값을 찾고
update 해줄 수 있다는 예시도 보여주고 싶었어요.
(rdb에는 array 개념이 없으니까요)
- group by 도 가능하다는 예시를 공유했어요
이 쯤 되니까 동기들이 지치더라고요
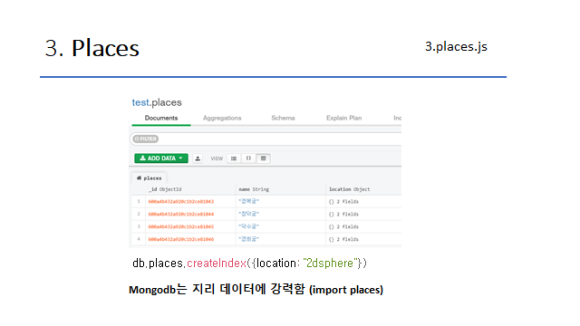
5. 예시 - Geodata
Places
Mongodb는 GeoData에 강해요 geodata 관련 글 중 아주 일부를 가지고 왔어요

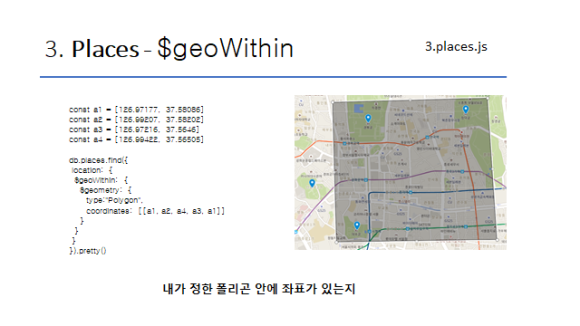
- 특정 좌표를 기준으로 *m 떨어져있는 모든 좌표를 구할 수 있어요
- 폴리곤을 만들어서, 안에 몇개 들어있는지도 볼 수 있죠
맨날 RDB만 보다보니까 이런게 너무 신기하더라고요
마무리
총 40분
30분을 목표로 했지만, 40분 정도 걸렸어요.
중간에 수다 떨고 그랬거든요
토요일 아침에 본사로 나온 불쌍한 제 동기들에게
이 PPT와 블로그 글을 바칩니다.
+ (글또 피드백 : @이주원, @배주훈)
NOSQL 끼리의 비교도 있으면 좋을 것 같아 추가합니다.
write 성능이 좋다는 장점이 있지만
Join이나 트랜잭션 처리가 불가능하다는 문제가 있어요
(저도 Mongodb만 해봐서 잘모르겟어요ㅜ)
|
DataStore
|
장 점
|
단 점
|
|
Cassandra
|
-대량으로 쓰기가 발생하는 서비스에 좋음
-확장성이 뛰어남
-Apache Foundation에서 개발중이며커뮤니티 활발
- Scale-Out
|
-최소 3대 이상 구성(클러스터 환경)
-복잡한 조건 검색 불가
-데이터 갱신 및 입력시 Atomic한 처리가 힘듬
|
|
HBase
|
-하둡 기반에서 동작하고 다양한 하둡 의 도구들과 상호 운영성이 좋음
-데이터 일관성 보장 우수(상대적)
|
-5대 미만에서는 사용할 수 없다(대규모 전용)
-성능이 좋진 않다 (상대적)
|
|
MongoDB
|
-스키마 없이 사용 가능
-SQL 과 비슷한 방식의 쿼리 사용
-몽고는 쓰기할때 메모리에 먼저 Write 후에
1분 단위로 Flushing하는 Write back 방식을 사용한기 때문에 write성능이 좋음
-Read시에는 파일의 Index를 메모리에 로딩해 놓고 찾는다(memory mapped file) - 빠름
-다양한 기능 제공
|
-JOIN이나 트랜잭션 처리가 불가능
-디스크에 쓰기가 비동기식으로 이루어진다. 때문에 경우에 따라 데이터가 유실될 가
|