회사에서 minio, spark, kuberenetes를 사용하게 되면서 유투브에서 좋은 자료를 찾아 따라했어요
유투브는 크게 2가지로 나누어지는데 이 게시물에서는 1번만 따라했어요.
1. minio on spark: minio > pyenv > spark-submit 로 결과 출력
2. kubernetes: sparkoperator를 이용해 kubernetes pod로 결과 출력
쉽게 따라할 수 잇었던 부분도 있고, 방화벽이나 네트워크 관련 문제 때문에 다른 방법을 사용하기도 했습니다.
1. minio 실행 후 pyspark로 결과 출력
- minio: helm으로로 minio 실행
- python: pyenv, pyenv-virtualenv 세팅
- spark: spark-submit main.py
Minio 환경 준비하기
> minio를 설치하고, json 파일을 올린 후 잘 올라갔는지 확인합니다.
minio는 s3와 호환되는 오브젝트 레포지토리로 테스트하기 위해서 기기 성능이 충분해야합니다.
(m1 macbook 8gb ram에 세팅하려다가 바로 메모리 부족 떴어요ㅜ)

1. minio 실행
> helm으로 설치를 진행합니다.
설치: https://helm.sh/docs/intro/install/
helm install --set accessKey=myaccesskey,secretKey=mysecretkey --generate-name minio/minio
2. minio 외부 공개
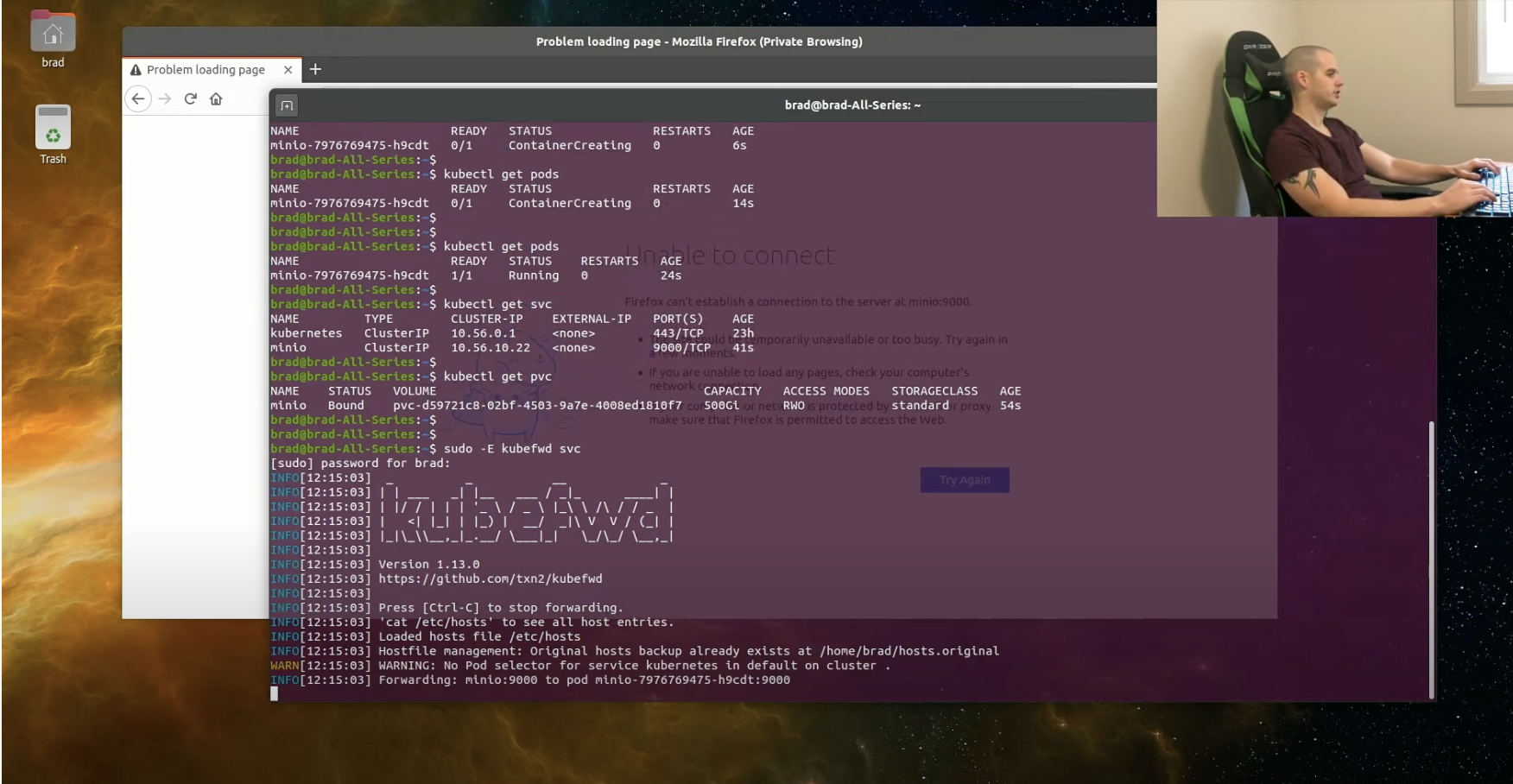
> kubefwd를 이용하는데, 저는 안되가지고 nodeport를 사용했습니다
$ minio-svc-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: minio-svc-nodeport
spec:
ports:
- name: minio
port: 9000
selector:
app: minio
type: NodePort
$ kubectl apply -f minio-svc-nodeport.yaml
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
minio-svc-nodeport NodePort 10.233.37.143 <none> 9000:31867/TCP 110m3. minio client 설치
minio client는 쿠버네티스 외부에 있기 때문에, nodeport로 노출시킨 port로 통신해야함
설치 : https://docs.min.io/docs/minio-client-complete-guide.html
# 설정에 minio9이라는 이름으로 alias를 설정합니다.
$ /.mc/config.json
{
"version": "10",
"aliases": {
"minio9": {
"url": "http://***.17.***.:31867/",
"accessKey": "myaccesskey",
"secretKey": "mysecretkey",
"api": "S3v4",
"path": "auto"
}
}
}
#bucket 만들기
$ /.mc mb minio9/test4. minio web에 들어가서 더미 데이터 넣기
> mc에서 만든 bucket이 만들어졌는지 확인하고, orders.json을 업로드합니다.

- http://***.17.***.86:31867/
- myaccessKey, mysecretKey
- orders.json {"id":1,"amount":1000} {"id":2,"amount":2000} {"id":3,"amount":5400}
5. minio client에서 결과 확인하기
> 결과를 확인합니다.
$ ./mc ls minio9/test
[2021-09-14 13:47:27 KST] 70B orders.json2. Python 환경 준비하기
> python, pyenv, pyenv-virutalenv를 설치합니다.
1. pyenv 설치
# libffi-devel가 pyenv install 보다 먼저 실행되어야함, 만약 설치가 이미되어있으면 pyenv uninstall 3.8.9, pyenv install -v 3.8.9
sudo yum install gcc zlib-devel bzip2 bzip2-devel readline-devel sqlite \
sqlite-devel openssl-devel xz xz-devel libffi-devel
# root로 다운로드
sudo -i
git clone https://github.com/yyuu/pyenv.git ~/.pyenv
git clone https://github.com/yyuu/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv
# 환경변수 설정
vi ~/.bashrc
(생략)
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
export SPARK_HOME=/root/project/spark-3.1.2-bin-hadoop3.2 #spark 경로
export PATH=$PATH:$SPARK_HOME/bin
export JAVA_HOME=/home/java/jdk1.8.0_301
export PATH=$PATH:$HOME/bin:$JAVAdd_HOME/bin
export PYENV_ROOT=/root/.pyenv
export PATH=$PYENV_ROOT/bin:$PATH
eval "$(pyenv init --path)"
eval "$(pyenv virtualenv-init -)"
# 반영
$ source ~/.bashrc2. pyenv 환경 구성
# 확인
pyenv versions
# 설치
pyenv install -v 3.8.9
# 다시 확인
pyenv versions
# 기본 버전 설정
pyenv global 3.8.9출처: https://realpython.com/intro-to-pyenv/
출처: https://rmohan.com/?p=7792
3. pySpark로 확인
> minio도 python도 설정이 되어있으면 pyspark를 실행해줍니다.
1. spark download
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
tar zxvf spark-3.1.2-bin-hadoop3.2.tgz
cd ./spark-3.1.2-bin-hadoop3.2
# jar가 없다고 에러가 나옴
## hadoop
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar
cp hadoop-aws-3.2.0.jar ./spark-3.1.2-bin-hadoop3.2/jars/
## aws-java-sdk
wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.375/aws-java-sdk-bundle-1.11.375.jar
cp aws-java-sdk-bundle-1.11.375.jar ./spark-3.1.2-bin-hadoop3.2/jars/2. pyenv 환경 설정 (pyspark)
mkdir sparkjob
cd ./sparkjob
# 파이썬 환경 3.8.9로 설정
pyenv virtualenv 3.8.9 job-3.8.9
pyenv local job-3.8.9
# pyspark 다운로드
$ cd job-3.8.9/
(job-3.8.9) root@kube01: ~/project/sparkjob/job-3.8.9:]# ll
(job-3.8.9) root@kube01: ~/project/sparkjob/job-3.8.9:] pip --trusted-host pypi.org --trusted-host files.pythonhosted.org install pyspark
python -m pip install --upgrade --trusted-host pypi.org --trusted-host files.pythonhosted.org pip3. main.py 만들기
$ vi main.py
from pyspark import SparkContext
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
def load_config(spark_context: SparkContext):
spark_context._jsc.hadoopConfiguration().set('fs.s3a.access.key', 'myaccesskey')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.secret.key', 'mysecretkey')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.path.style.access', 'true')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.impl', 'org.apache.hadoop.fs.s3a.S3AFileSystem')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.endpoint', 'http://***.17.***.86:31867') //nodeport로 외부에 공개된 port 설정
spark_context._jsc.hadoopConfiguration().set('fs.s3a.connection.ssl.enabled', 'false')
load_config(spark.sparkContext)
dataframe = spark.read.json('s3a://test/*') //orders.json 파일 선택
average = dataframe.agg({'amount': 'avg'}) //orderjs.json 파일의 amount의 평균값
average.show()
4. spark-submit main.py
> main.py 실행
#환경 변수에 spark-submit 잡혀있음
$ spark-submit main.py
(생략)
+-----------+
|avg(amount)|
+-----------+
| 2800.0|
+-----------+
21/09/14 15:47:05 INFO SparkUI: Stopped Spark web UI at http://kube01:4040
21/09/14 15:47:05 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!+ Curl -x GET으로 MINIO 결과 확인하기
> spark-submit을 사용하지 않고, curl로 확인할 수 없을까 찾아봤어요
1. curl용 POD 실행
$ kubectl run -i --tty --rm debug --image=alicek106/ubuntu:curl --restart=Never bash
$ kubectl get pod -o wide2. Curl 로 결과 확인
> pod 내부의 통신이기 때문에 pod의 IP를 입력해야합니다.
아래 명령어를 입력하면, minio의 결과가 나오는 것을 확인할 수 있어요
# 여기서 host는 pod의 ip, cluster가 아님
$
bucket=test
file=orders.json
host=10.233.98.120:9000
s3_key='myaccesskey'
s3_secret='mysecretkey'
resource="/${bucket}/${file}"
content_type="application/octet-stream"
date=`date -R`
_signature="GET\n\n${content_type}\n${date}\n${resource}"
signature=`echo -en ${_signature} | openssl sha1 -hmac ${s3_secret} -binary | base64`
curl -v -X GET \
-H "Host: $host" \
-H "Date: ${date}" \
-H "Content-Type: ${content_type}" \
-H "Authorization: AWS ${s3_key}:${signature}" \
http://$host${resource}
(결과)
+-----------+
|avg(amount)|
+-----------+
| 2800.0|
+-----------+
글이 길어져서,
2. kubernetes: sparkoperator를 이용해 kubernetes pod로 결과 출력
은 따로 나눴었요 ㅎ
https://mightytedkim.tistory.com/28
Kubernetes) How to run Spark with Minio in Kubernetes_2
회사에서 minio, spark, kuberenetes를 사용하게 되면서 유투브에서 좋은 자료를 찾아 따라했어요 유투브는 크게 2가지로 나누어지는데 이 게시물에서는 sparkoperator를 따라했어요. 1. minio on spark: minio >..
mightytedkim.tistory.com
'기타 > K8S' 카테고리의 다른 글
| Kubernetes) Metrics server 오류_kubelet-insecure-tls (0) | 2021.11.16 |
|---|---|
| youtube) k8s+spark+minio 실습 따라하기_2 :: mightytedkim (0) | 2021.09.21 |
| Slipp) K8S 스터디4주차_디플로이먼트, 서비스, 잡 :: mightytedkim (0) | 2021.09.20 |
| Slipp) K8S 스터디3주차_minikube 실습 :: mightytedkim (0) | 2021.09.11 |
| Slipp) K8S 스터디2주차_컨테이너의 개념 :: mightytedkim (0) | 2021.08.26 |