당장 kafka 코드를 짤일은 없어서, 빠르게 kafka인강을 들었어요
지금 몰라도 될 것 같은 부분은 빠르게 스킵했습니다.
---
Kafka 인강) Apache Kafka Series - Learn Apache Kafka for Beginners v2_udemy
강사는 Stephane Maearek. 프랑스 출신인 것 같고,
kafka, aws에 엄청 핫한 강사에요.
수강평이 2.2만개 ㅋㅋㅋㅋㅋ 역시 믿음의 유데미
가격도 할인해서 1.4만원 뿐이 안했어요

7시간 32분인데, 보통 3배 정도 더 걸리더라고요.
요즘 바쁜 시기니까 1달 정도 잡을라고요
19 sections • 123 lectures • 7h 32m total length
1. Kafka Intoduction
4 /10m
카프카가 무엇인지 소개해주는 10분짜리 개요인데,
이 강의의 목표에 대해서 구체적으로 정의해주는 부분이 좋았어요.
기본 강의지만, 작은 프로젝트에 적용할 수 있을 정도의 능력을 갖출 수 있을 거라고 해요
Preview 02:20
카프카 소개
Preview 05:20
- 링크드인에서 만들어졌고, confluent에서 유지하는 오픈소스
- 고가용성, 스케일업
- 메시징, 트래킹, 지리 정보 수집, 로그 수집, 스트림 프로세싱, 빅데이터 인프라 등
- 사례
- 넷플릭스 : 실시간 추천
- Uber: 실시간 운행 정보 예측
- linkedin : 스팸 방지, 사용자 추천
Course Objectives 01:47
- 기초 : 3시간
- 사례 :3.5 시간 (트위터, es, api)
- 심화 : 토픽 설정 등
Important Message 00:24
Code Download 00:14
2. Kafka Theory
11 /38m
카프카 기본 이론에 대해서 알려주는데,
토픽, 파티션, 오프셋의 개념에 대해서 상세히 알려줍니다.
카프카에 데이터를 넣어놓으면, 컨슈머에서 필요에 따라 가져가는 방식으로 사용이 된다는 설명이 너무 좋았어요
Kafka Fundamentals 00:19
Kafka Theory Overview 00:29
Preview 06:47
- Topics, Partitions and Offsets
- Topic : stream of data (table)
- Partition
- offset : incremental id
Brokers and Topics 03:19
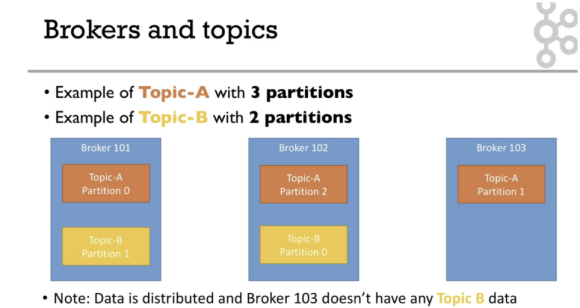
- Brokers and Topics
- Kafka cluster는 다수의 브로커(서버)로 구성
Topic Replication 04:12
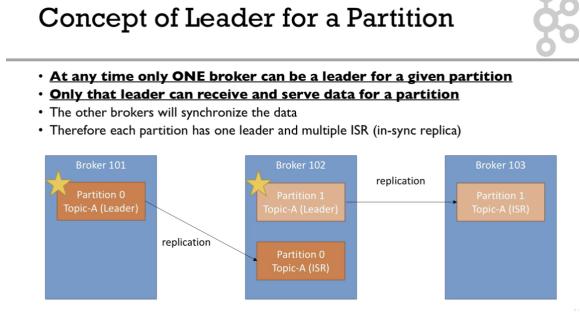
- replication은 데이터 보존을 위해서 필요
- leader는 데이터를 받거나 보내고 항상 1개
- follower는 leader의 데이터를 싱크
- ISR : in-sync replica
Producers and Message Keys 05:25
- acks
- 0 : dont wait (possible loss)
- 1 : wait for Leader (limited)
- all : Leader + replicas (no loss)
- Message Keys
- null → RR
- all message goes to same partition
Consumers & Consumer Groups 04:37
consumes data from topic
consumers == partitions
Consumer Offsets & Delivery Semantics 04:39
- __consumer__offsets: offsets are committed in topic
- if consumers die, can resume
- delivery semantics (커밋 시점)
- At most once : as soon as message received
- At least once : after message is processed
- (가장 많이 사용) 중복 고려해서 시스템 짜야
- Exactly once : kafka 끼리 (streams API 로 가능)
Kafka Broker Discovery 02:23
bootstrap server라고 부르는데, 하나만 연결해도 됨
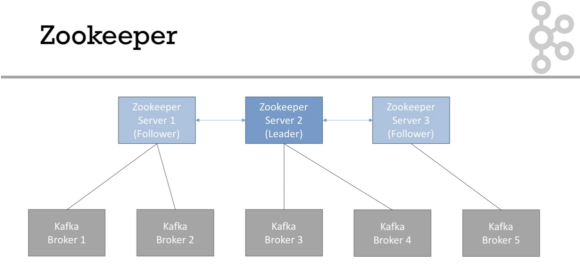
Zookeeper 02:42
- broker를 연결
- 리더를 선출
- kafka에 변경 사항 전달(새 토픽, 브로커 죽음, 브로커 살아남 등)
- Zookeeper가 필수
- Consumer Offset을 더 이상 저장하지 않음(>v0.10)
Kafka Guarantees 01:09
- topic partition에 메시지에 적재
- 순서대로 저장됨
Theory Roundup 01:58
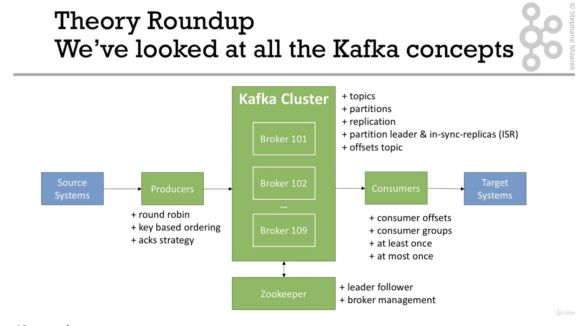
Quiz on Theory 13 questions
Starting Kafka
12 /38m
카프카를 설치하는데, 저는 맥북에다가 설치해서 빠르게 했어요 :)
Important: Starting Kafka 00:23
FAQ for Setup Problems 00:44
Mac OS X - Download and Setup Kafka in PATH 04:44
Mac OS X - Using brew 01:29
Mac OS X - Start Zookeeper and Kafka 05:37
Mac OS X - Summary 00:17
Linux - Download and Setup Kafka in PATH 05:34
Linux - Start Zookeeper and Kafka 04:56
Linux - Summary 00:19
Windows - Download Kafka and PATH Setup 08:13
Windows - Start Zookeeper & Kafka 04:59
Windows - Summary 00:21
CLI Introduction 00:23
WINDOWS WARNING: PLEASE READ 00:19
3. CLI (Command Line Interface) 101
12/ 40m
기본적인 명령어들에 대해서 알려줘요.
어떤 명령어를 입력해야 하고, help 를 보면서 문제를 해결하는 방법을 알려줘서 도움이 되었어요
예시 코드에 이쁘게 정리되어 있어요 ㅎ
Kafka Topics CLI 07:32
Kafka Console Producer CLI 07:08
Kafka Console Consumer CLI 03:21
Kafka Consumers in Group 06:29
Kafka Consumer Groups CLI 04:13
Resetting Offsets 04:07
CLI Options that are good to know 00:10
What about UIs? Conduktor 00:28
Conduktor - Demo 06:03
KafkaCat as a replacement for Kafka CLI 00:09
Quiz on CLI 7 questions
4. Kafka Java Programming 101
11/ 55m
자바 프로그래밍을 하나씩 따라서 입력해줘요
단순히 CLI로 세팅하는 것을 넘어서, 실제 코드 사용 사례를 배워서 좋았어요
자바 부분은 코드로 따라쳐서, 따로 메모할 게 없네요 ㅎ
Intro to Kafka Programming 00:25
Installing Java 8 & IntelliJ Community Edition 00:09
Creating Kafka Project 06:24
Java Producer 10:49
Java Producer Callbacks 06:52
Java Producer with Keys 06:08
Java Consumer 11:49
Java Consumer inside Consumer Group 06:29
Java Consumer Seek and Assign 04:22
Client Bi-Directional Compatibility 01:17
Configuring Producers and Consumers 00:06
Quiz on Java Programming 101 9 questions
5. Kafka Twitter Producer & Advanced Configurations
15/ 65m
트위터 API를 자바로 받아서, kafka로 쏘는 실습을 해요.
받은 메시지들을 어떻게 활용하는지 예시를 보여줘요.
Real World Project Overview 00:45
Real World Exercise 00:16
Producer and Advanced Configurations Overview 00:28
Twitter Setup 04:44
Producer Part 1 - Writing Twitter Client 10:13
Producer Part 2 - Writing the Kafka Producer 07:46
Producer Configurations Introduction 00:48
acks & min.insync.replicas 06:15
- 0 1 all 이 있고, 이 설정값들은 중요함
retries, delivery.timeout.ms & max.in.flight.requests.per.connection 04:45
Idempotent Producer 04:29
- 중복값을 kafka에서 자동으로 조절해줌
Producer Part 3 - Safe Producer 05:15
Producer Compression 04:44
- gzip, snapp, l4 등이 있음
Producer Batching 04:51
- 알아서 배치로 카프카가 날림, 하나의 request로 보냄
- default : 0, 바로 보냄
- linger.ms=5, lag를 만들어서 효율성을 높임
- 기다릴때 쌓이는 메시지가 batch.size보다 커지면 보냄
- 압축해서 보내기 때문에 효율적
- batch.size
- default: 16kb
- batch 이상의 크기는 진행되지 않음
Producer Part 4 - High Throughput Producer 03:07
- snappy : 구글에서 만든것
- 실습
- snappy는 json과 같은 text에 적합하고, CPU 를 효율적으로 사용
- batch.size : 32kb, linger.ms : 20ms
Producer Default Partitions and Key Hashing 02:24
- 해시되는 방법
- murmur2 알고리즘
[Advanced] max.block.ms and buffer.memory 02:30
Quiz on Producer Configurations 6 questions
Refactoring the Project 03:04
- 되도록이면 건드리지 말 것
- buffer 메모리가 꽉 차면, 그대로 멈춤
- max.block.ms=60000는 예외처리하기 전까지의 시간
6. Kafka Elasticsearch Consumer & Advanced Configured
14/ 59m
제가 좋아하는 es와 연결하는 예시에요
Idempotence, commit 설정 등의 중요 개념을 설명해준답니다.
트위터에서 받은 메시지가 카프카를 거쳐서 es로 넘어가는 것을 볼 수 있어요
Consumer and Advanced Configuration Overview 00:27
Setting up ElasticSearch in the Cloud 03:13
- 본자이 에서 공짜 es 클러스터 제공받기
ElasticSearch 101 05:47
- es 헬로우 월드
Consumer Part 1 - Setup Project 08:22
- 트위터 api 결과를 es에 넣기
Consumer Part 2 - Write the Consumer & Send to ElasticSearch 06:21
Delivery Semantics for Consumers 04:11
- At most once : 메시지 배치가 도착하면 offset 이 바로 commit
- 배치로 돌리다 보면, 아래 그림처럼 비는 데이터가 생길 수 있음
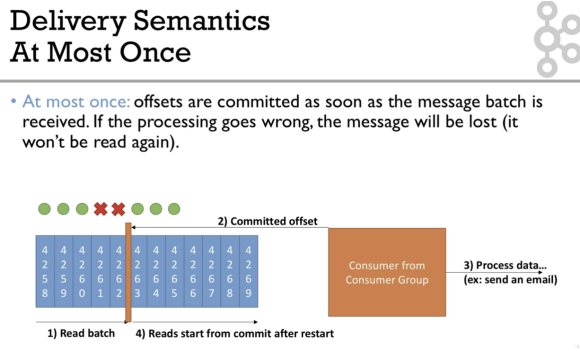
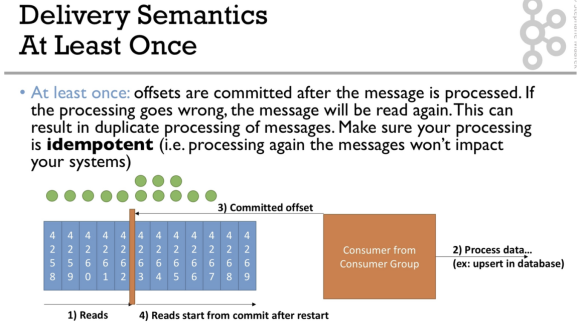
- At least once :
- 데이터 process 완료하고, offset commit
- 중복이발생할 수 있기 때문에, idempotent 가 중요
- exactly once : kafka → kafka 에서 사용되는데 kafka-streams 할 때 배움
Consumer Part 3 - 07:45
- 중복 값을 조정하기위한 설정 값properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
Consumer Poll Behaviour 02:58
- 기본 설정을 건드릴 일은 거의 없지만, 알아둘 필요는 있음
- Fetch.min.bytes(default 1) : latency
- Max.poll.records(default 500) : ram
- Max.partitions.fetch.bytes(default 1mb)
- Fetch.max.bytes(default 50mb)
Consumer Offset Commit Strategies 02:44
- commit하고 나서의 행동
- enable.auto.commit = true + synchronous procesing of batches
- 5초마다 offset이 커밋 해줌 (auto.commit.interval.ms=5000)
- asychronouse 사용하면, 데이터가 processe되기 전에 커밋되서 의미가 없어짐
- enable.auto.commit = false + synchronous processing of batches
- commit 시점을 조절할 수 있고, buffer로 작업할 대 유용함
Consumer Part 4 - Manual Commit of Offsets 04:39
- 특정 위치에서 싱크를 맞추는 방법
Consumer Part 5 - Performance Improvement using Batching 05:39
- es bulk 활용
Consumer Offsets Reset Behaviour 02:06
- consumer가 죽으면, 7일 뒤에 offset 상태가 invalid가 됨 (consumer는 연속적인 거니까)
- auto.offset.resets=latest/earliest/none
- 데이터가 날라갈 수 있음. 2.0 이상에서는 7일, 그 전에는 1일
- offset.retention.minutes
- consumer group 데이터를 다시 실행하려면
- group을 내리고 kafka-consumer-groups 명령어를 이용해 offset을 새로 생성해야함
Consumer Part 6 - Replaying Data 01:58
- ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group kafka-demo-elasticsearch --reset-offsets --execute --to-earliest --topic twitter_tweets
Consumer Internal Threads 03:01
- heartbeat thread
- Session.timeout.ms(default 10 seconds)
- Heartbeat.interval.ms(default 3 seconds) : 보통 세션 타임아웃의 1/3
- max.poll.interval.ms(default 5 minutes)
Quiz on Consumer Configurations 6 questions
7. Kafka Extended APIs for Developers
6/ 33m
Kafka in the Real World 00:47
Kafka Connect Introduction 04:47
- 대표적인 kafka 사용 방법
- source → kafka : Producer API ⇒ Kafka Connect Source
- kafka → kafka : Consumer, Producer API ⇒ Kafka Streams
- kafka → sink : Consumer API ⇒ Kafka Connect Sink
- kafka → app : Consumer API
- kafa connect란?
- 제3자가 만든 패키지들
Kafka Connect Twitter Hands-On 08:07
- 예시) 설정값 몇개로 twitter producer를 구동

코딩 엇이 설정값으로 세팅할 수 있음
Kafka Streams Introduction 03:20
- 데이터 transformation 방법
- stanadard java application
- high scalability
- one record at a time
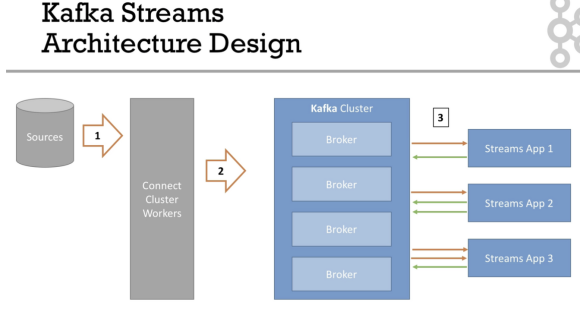
Kafka Streams Hands-On 11:57
- 예시)
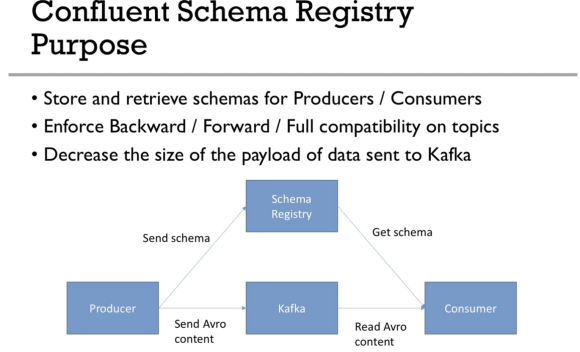
Kafka Schema Registry Introduction 04:41
- 스키마 관리
- conlfuent schema registry
Which Kafka API should I use? 00:09
Quiz on Kafka Extended APIs 5 questions
8. Real World Insights and Case Studies (Big data / Fast Data)
6/ 33m
페이스북, 우버, 넷플릭스 등의 사례들을 예시로
어떻게 카프카를 활용할 수 있는지 짧게 설명해줘요,
앞에서 배웠던 추상적인 개념을 정리할 수 있어서 좋았어요
Choosing Partition Count & Replication Factor 08:36
- 가장 중요한 파라미터 2가지
- partition count : 처음부터 잘 설계해야하고, 테스트가 곡 필요함
- better throughput
- partition per topic
- small cluster (< 6 brokers) = 2* #of brokers
- big cluster(>12 borkes) = 1 * #of brokers
- replication factor
- 3로 고정, 절대 1로 설정하지 말것
Kafka Topics Naming Convention 00:08
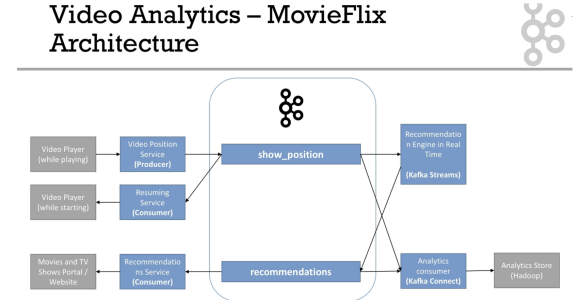
Case Study - MovieFlix 05:08
- 넷플릭스와 같은 서비스를 하는 회사는 어떻게 할까
- 설명
- show_position
- 복수의 producer
- 많은 양의 partitions
- pk 는 user_id
- recommendation
- 분석용
- 적은 양의 볼륨
- pk는 여전히 user_id
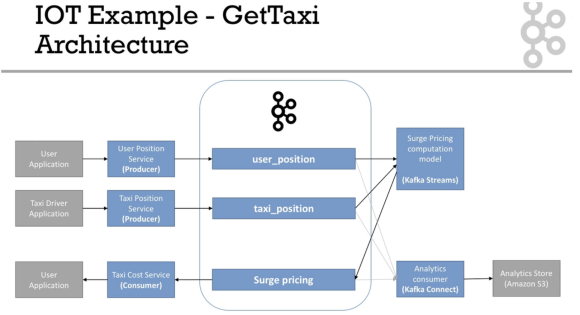
Case Study - GetTaxi 04:18
- 우버와 같은 예시
- 설명
- taxi_position, user_position
- 복수의 producer
- 많은 양의 partition
- pk는 user_id, taxi_id
- data는 일시적이어서, 긴 retention 시간이 필요 없음
- surge_pricing
- kafka-streams 에서 데이터가 옴
- 많은 양의 partition
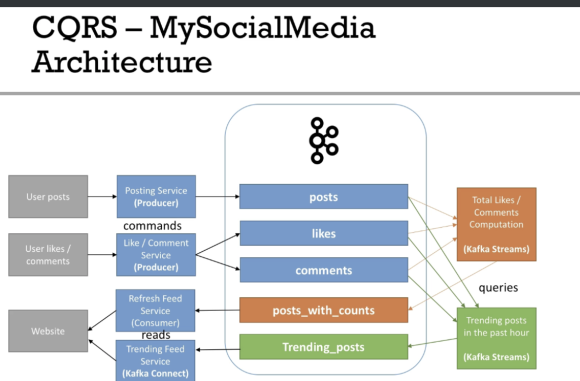
Case Study - MySocialMedia 05:32
- 페이스북 같은 예시
- kafka → kafka : kafka-streams
- post + likes + comments
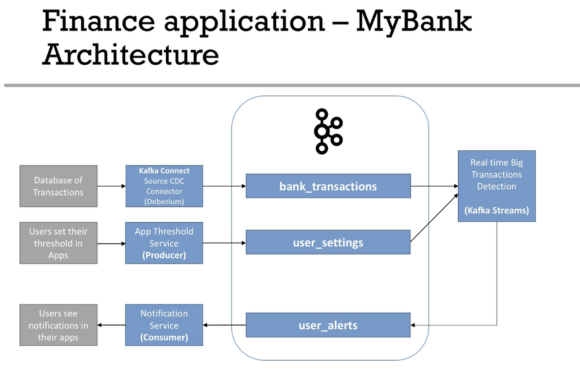
Case Study - MyBank 03:41
- 디비지움을 이용한 rdb와 연결 작업
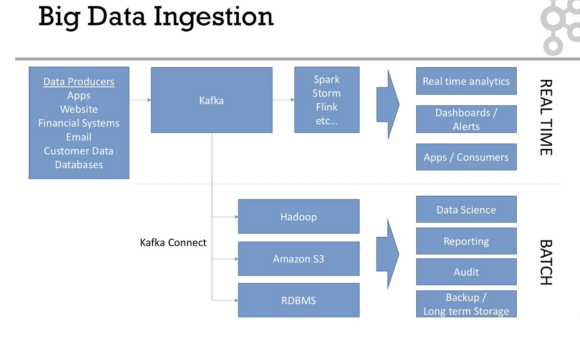
Case Study - Big Data Ingestion 01:48
- 실시간과 배치 작업으로 크게 빅데이터 인프라가 구성됨
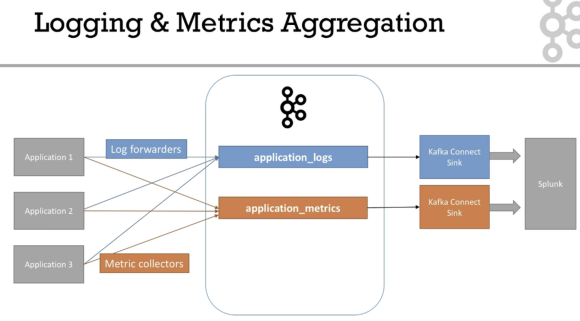
Case Study - Logging and Metrics Aggregation 01:59
- 일반적으로 여러 곳에서 로그를 쏘고, 카프카가 중앙에서 관리함
9. Kafka in Enterprise for Admins
8/ 31m
Kafka Cluster Setup High Level Architecture Overview 02:42
Kafka Monitoring & Operations 02:58
Kafka Security 05:01
Kafka Multi Cluster & MirrorMaker 06:48
10. Kafka in Enterprise for Admins
6/ 33m
Advanced Kafka 00:10
Changing a Topic Configuration 04:42
Segment and Indexes 05:11
Log Cleanup Policies 02:30
Log Cleanup Delete 02:07
Log Compaction Theory 06:04
Log Compaction Practice 07:02
min.insync.replicas reminder 03:04
Unclean Leader Election 01:17
11. Annex - Starting Kafka Differently
6/ 33m
What are annexes? 00:33
Annex 1 - Overview 00:33
Starting Kafka with the Confluent CLI 02:59
Starting a multi broker Kafka Cluster using Binaries 06:32
Note on Docker Setup 00:31
Start Kafka Development environment using Docker 04:20
Starting a multi broker Kafka Cluster using Docker 02:55
Kafka Advertised Host Setting 03:25
Starting Kafka on a Remote Machine 05:42
12. Next Steps
6/ 33m
What's Next? 01:22
THANK YOU! 01:32
Bonus Lecture: Student Special Coupons for my Other courses 01:01
'Data > Kafka' 카테고리의 다른 글
| kafka) kafka_exporter 설정 (prometheus,helm) (0) | 2022.08.05 |
|---|---|
| kafka) cmak 설치 (kafka manager) (0) | 2022.07.28 |
| kafka) kafka cluster 설정 (0) | 2022.07.28 |
| kafka) zookeeper cluster 설정하기 (0) | 2022.07.28 |