https://www.udemy.com/course/apache-airflow-the-operators-guide/learn/lecture/21553710?start=0#overview
kubernetes Pod Operator 공부할 때 참고했던 사람의 강의였기 때문에 신뢰가 감
ETL파이프 라인을 실무에서 세팅하는 방법을 급하게 알아야하기 때문에 좋음
심지어 버전도 2.x임, 회사에서 2.1.4사용하고 있어서 너무 좋음
총 7시간이고 해당 포스트는 1,2 섹션 메모용

Section 1: Introduction 5/5 10min
1. Important Prerequisites 2min
specific operator에 대해서 배우는 강의
airflow 기본에 대해서 알고 있어야함
3. Course Objectives 3min
dag dependency와 다양한 operator에대해서 배우게 됨
4. Who am I? 1min
astronmer.io custromer training head
data engineer
best selling instructor on airflow udemy
5. Development Environment
docker-compose
Section 2: The BaseOperator Exposed 26/26 3hr 28min
6. Introduction 5min
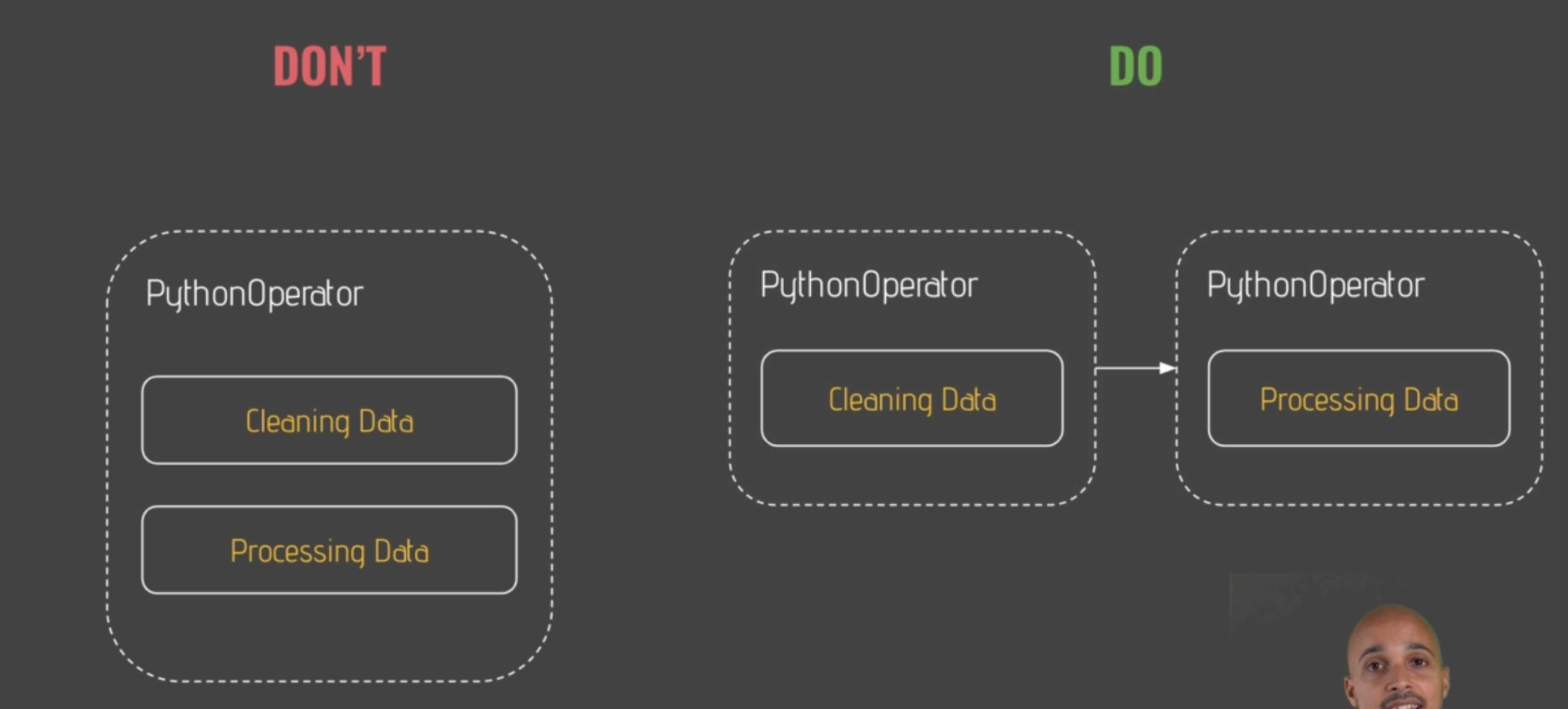
Bash Operator에 대해서 알려주며, 근본을 알아야한다고 강조함
파이프라인의 안전성을 가져오는 것은 중요함
BaseOperator라고 무시하면 안됨
- trigger, 알람, 사용자 정의 항목 등을 활용하면 매우 강력해짐
- parent가 안돌아도 실행하거나, 병렬로 몇개를 실행할건지
- 실패했을 때 어떻게 할건지
7. What you need to know 9min
Operator의 특징에 대해 알려주는데, 너무 좋았음
operator란? - 데이터 파이프라인의 캡슐화된 작업
- operator 당 1개의 task 를 할당해야함
- 3개의 operator
* Action Operators: Execute an action(ex. python, bash, etc)
* Transfer Operators: Trasfer data
* Sensors: wait for a condition to meet #s3에 로그 저장하는 거)
Idempotency -> same input, same ouput
Context
def _my_function_(**context): #airflow 2.xx 이후 부터는 provide_context=True 생략 가능
def _my_function_(ds): #current execution date
모든 operator는 BaseOperator를 상속함
8. Important details 3min
BashOperator가 근본이라는 걸 알려줌
BashOperator #자세히 보기, 중요한 함수
1. execute(self, context): #custom operator 만들때 필요
2. pre_execute(self, conetxt) # 실행 직전
3. post_execute(self, conetxt) # 실행 끝나고 종료 직전
4. on_kill #thread 작업할 때 매우 중요, 좀피 프로세스 죽일 때
5. run #실행하기 위해 개별 오퍼레이터 적용
9. The task id exposed! 5min
task_id, 중복나면 에러나는 것을 알려줌
task_id : unque identifier of the task -> 중복되면 에러남
- 구체적일 수록 좋음
- String
- maximum length 250 #근데 너무 길면 kubernetes pod name, dag_id와 함께 63글자를 넘어가서 오류남
- alpha, dash, dot, underscore 로만 구성되어야함
- task_id는 동적으로 구성될 수 있음 #정보가 있으면 가능함, For문으로 가능했던것같은데
10. Dag versioning 14min
dag versioning 얼탱 없음... 그냥 dag_id를 바꾸라함
dealing with changes over time
문제: task_id 막 바꾸면 과거 내역 날라갈 수 있음
해결: 방법 없음 ㅋㅋㅋ이게 공식 답변임
그나마 컨트롤 할 수 있는게 아래 방법
with DAG(dag_id="my_dag_v_1_0_0",
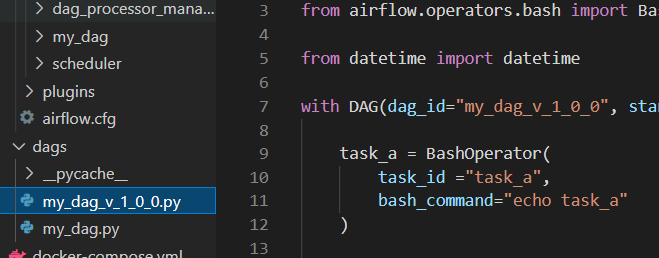
불편할 수 있지만 과거 내역을 볼 필요가 있기 때문에 이렇게 관리하는게 맞다고함
그런데 실제 이렇게하면 귓방망이 맞을거같은데.. 좀 아쉽다.
11. Who owns the task? 9min
owners, 처음 알았던 개념 디테일 ㅋㅋ
- default_args = { owner="airflow" } #filter로 검색할 수 있기 때문에 유용함
airflow2.0.0 에서 달라짐
- 각 task 별로 owner를 설정할 수 있음
|
t1 = PythonOperator(
task_id='t1',
python_callable=hello,
owner='hgkim',
dag=dag,
)
t2 = PythonOperator(
task_id='t2',
python_callable=hello,
owner='tedkim',
dag=dag,
)
|
audit_logs 에서 Owner가 무슨 작업했는지 볼 수 있음
- user 또는 task의 owner 중 어느 것인지 구분할 필요가 있음
- 어떤 task는 task의 owner가 표시됨
- 어떤 task는 airflow 같은 user가 표시됨(ex. cli_task_run)
12. The start_date is more than you think 15min
start_date, schedule_interval, 아주 중요한 개념
catchup=False 까지 알려줘서 좋음
- false로 해도, 가장 최근 job이 실행될 수 있음
그럴 떼 datetime.now()하면 실행하면 현재 시점으로 시작하니까 1개의 job만 실행됨,
|
dag = DAG(
'my_dag',
start_date=datetime.now(),
schedule_interval='*/1 * * * *',
catchup=False,
tags=['hgkim']
)
|
하지만 days_ago로 하는 것을 추천
-------
task마다 start_date를 줄 수 있지만, 그럴 이유가 딱히 없음. 하지말 것을 추천
13. Retry your task! 17min
task가 실패했을 떄, api 가져올 때 유용함, 실패할 수 있으니까
- bash_command="echo 'task_b' && exit 1"
- retries=3
- retry_delay=timedelta(seconds=10), bash_command="sleep 5 && exit 1"
- retry_exponential_backoff=True -> 재시작 시작 시간이 계속 길어짐
- {{ti.try_number}} -> 재식작 횟수를 알 수 있음
14. Be PROPERLY notified by emails 21min
실패했을 때 email 보내기, 이거는 내부망에서 smtp 정보 받아서 진행해야겠음 편할듯
configure airflow to be notifies by email -> google 예시
airflow.cfg
[smtp]
smtp_host = smtp.gmail.com
smtp_user = xxx#@gammail.com
smtp_password = ryvbqekntdzoakwe #google에서 생성한 내용
smtp_port = 587
smtp_mail_from=xxx#@gammail.com
dags
- param
- email = [xxxx@naver.com]
- email_on_retry
- email_on_failure
docker exec -it [airflow-scheduler]
- airflow tasks test [dag_id] [task_id] [2021-01-01]
html_content_template=/opt/airflow/includes/content_template.txt -> 제목
airflow alert: {{ti.task_id}}
subject_template=/opt/airflow/includes/subject_template.txt -> 내용
Try {{tryp_number}} out of {{max_tries + 1}}
Execution date: {{ti.execution_date}}
15. Make your tasks dependent between DAGRuns 10min
depends_on_past=True 예시로 dead lock 걸릴 수 있으니
dagrun_timeout=40 습관 가지라고 이야기해줌, default job 이 16개까지만 되니까
16. Wait for downstream tasks 11min
선행 task 가 성공해야지 뒤에 작업이 실행됨
depends_on_past -> 선행 task 가 성공해야지 뒤에 작업이 실행됨
wait_for_downstream : 사실 정확히 이해가지 않음
-> depends_on_past가 true 됨, 앞의 job가 성공해야지 작동됨. (에러난 job을 뒤의 scheudle interval로 계속 실행하지 않음)
- 모든 task를 확인하는게 아니라, task에 해당 설정값이 정의된것만 확인 (direct downstream tasks)
ex.) 같은 리소스를 여러 job들에서 사용할 경우
    
   
| 1 |
2 |
3 |
Read
- wait_for_downstream=True |
Read
- wait_for_downstream=True |
Read
- wait_for_downstream=True |
| Drop |
Drop |
Drop |
| Create |
Create |
Create |
api 받아오는 경우 한번에 많은 요청이 가면 오류가 날 수 있기 때문에, 동시에 여러개가 실행되지 않게하는 이 작업은 의미가 있을듯
17. Pool party! 12min
순차적으로 진행되는 작업, 동시에 진행될 수 잇는 작업 수를 보기 위해서 알아야함
pool 관리하는 것은 중요함
최댄 32개까지 동시에 돌 수 있고, 작업이 큰 경우에는 순서를 정해서 진행할 수 있음
18. Task priority 9min
priority_weight
높을 수록 중요도가 높아짐. 기본적으로 1임. 그래서 어떤게 먼저 실행될지 모름
A (1) ->
B (2) -> D (6)
C (3) ->
결과 : C-> B-> A -> D (앞의 dependency가 우선)
동일한 pool에 있을 때만 효과가 있음, 따라서 pool도 신경써야함
Pool A : task a(4), task b(3)
Pool B : task c(2) task d(1)
weight_rule
모든 task는 동일한 weight을 가지고 있는데, 이게 upstream/downstream등에 따라 달라짐
(downstream)
A(4) -> C(3) -> E(2) -> F(1)
B(3) -> D(2) --------------
결과 : depth가 깊을 수록 달라짐, A->B->D->D->E->F
(upstream)
A(1) -> C(2) -> E(3) -> F(6)
B(1) -> D(2) --------------
결과: 총 6, 이걸 나눠가짐, A->B->D->D->E->F
그럼 upstream은 왜 필요한가?
-> 실무에서는 큰 의미 없음.
(absolute)
A(5) -> C(2) -> E(3) -> F(6)
B(6) -> D(2) --------------
결과: 절대값 B->A->D->D->E->F
19. Define the priority! 1min
process_a = BashOperator(
owner='marc',
task_id="process_a",
retries=3,
retry_exponential_backoff=True,
retry_delay=timedelta(seconds=10),
bash_command="echo '{{ ti.try_number }}' && sleep 20",
priority_weight=2, # HERE
pool="process_tasks"
) |
20. Change task execution with trigger_rules 7min
부모가 성공해야 trigger_rule이 실행됨
all_success : t1,t2 둘다 성공해야 t3 실행됨
all_failed : t1,t2가 둘아 실패하면 t3 실행됨
all_done : t1,t2가 완료되면 t3 실행됨
one_failed: t1 or t2 중 하나만 실패해도 t3 실행함(skip이 있으면 t3도 skip)
one_success: t1 or t2 중 하나만 성공해도 t3 실행함(skip이 있으면 t3도 skip)
none_failed: t1,t2 가 성공 또는 skip될 때 t3 실행함, 둘중 하나만 실패해도 t3 upstream_failed
none_failed_or_skipped: t1,t2이 모두 실패나 skip이 아닐 때 t3 실행
none_skipped: t1,t2 skip 안되면 실행
21. Execute cleaning tasks with trigger_rules 2min
22. Set expectations to your tasks with SLAs 13min
너무 오래걸리면 warining 받을 수 있음. 2가지가 있음
1. 이메일
2. dag_parameter call_back
airflow.cfg
check_slas=True #default
def _sla_miss(dag, taslk_list, blocking_task_list, slas, blocking_tis):
print(f"SLAS for dag: {dag} - SLAs: {slas}")
dag (
sla=timedelta(seconds=15) # 15초 이상 걸리면 waring 걸림, email로 바로 전달됨
sla_miss_call_back=_sla_miss # 함수를 부를 수 있음
)
* 그런데 실무에서는 잘 사용하지 않음. 문제 많음
t1(1m) > t2(2m) > t3(3m)
왜냐하면 execution_date에 따라 달라짐
execution_date이 2021/01/01 10:00인데
- task 시작 시간이 아닌거, 전체 job 기준임
차라리, execution_timeout을 진행하는걸 추천함
sla_missed에 표시되는것도 첫번째가 아니라 두번째에 표시됨
23. Timeout 5min
data pipeline이 죽지 않고 stuck 될 수 있는 상황을 고려
execution_timeout=timedelta(seconds=12)
하지만 execution_timeout가 slas는 다름
SLA는 그냥 warning, timeout은 fail 때림
24. Define a timeout 1min
여기는 아무 내용이 없
25. A callback to react 6min
1. on_success_callback=_extract_a_on_success
def _on_success_callback=_extract_a_on_success(context):
print(context)
2. on_failure_callback=_extract_a_on_failure
def _extract_a_on_failure=_extract_a_on_failure(context):
print(context)
exception이 나오는데, 이걸 잘 활용하면 좋음
3. on_retry_callback
4. on_failure_callback
26. Catch a timeout with the failure callback 1min
27. Share data with the famous XCOMs 13min
xcom, task간 파라미터 전달할 수 잇음
- key: value
설정 : do_xcom_push=True 이어서,
xcom_push()가 가능함
return value로도 진행 가능함
작은 양의 데이터만 주고 받음.
DB별로 xcom 용량이 다름
- sqlite(2G), pgsql(1G) mysql (64kb)
do_xcom_push=True
do_xcom_pull=False
UI에서 admin > XComs에서 값을 볼 수 있음
ti.xcom_pull(task_ids=['process_a','process_b','process_c'], key='return_value')
28. Limit the concurrency 5min
pool과는 다른 task 레벨의 concurrency
Pools : limit concurrency subset of tasks
task_concurrency : limit concurrenct of task id
backfilling 할 때 너무 많은 부하가 걸릴 수 있는데, 이걸 줄일 수 있음
task_concurrency=1
29. Chain and Cross dependency helpers 7min
더 좋은 표현법
from airflow.models.baseoperator import cross_downstream, chain
| t1 >> t2
t1 >> t3
t1 >> t4
|
cross_downstream(t1, [t2,t3,t4]) |
다른 예시
t1 >> t3
t1 >> t4
t2 >> t3
t2 >> t4
|
chain([t1,t2], [t3,t4])
# list의 길이가 동일해야함
앞에 t0넣어도됨chain(t0,[t1,t2], [t3,t4])
# list의 길이가 동일해야함 |
31. Customize your task according to the executor 5min
kubernetes executor 사용하려고 airflow 삽질 엄청했는데, 그냥 이거 인강 볼걸 그랬다 ㅜㅜ
kubernetes executor는 task마다 cpu, memory를 정의할 수 있기 때문에 좋음
하지만 airflow 업데이트될때까지 기다려야함
airflow 2.0은 k8s api를 이용해 설정할 수 잇기 때문에 좋음
pod_override, pod_template_file 을 사용할 수 있음
아 빡셋다. 그래도 알고 사용안하는것과 모르는것은 천지차이라서
나중에 적용할 때 참고해야겠다. 기존 파이프라인 건드리는건 위험해서 일단 패스