
스터디를 통해 배운 내용을 실무에 정리한 글이에요
책의 8장 내용 custom operator를 참고했습니다.
airflow를 운영하면서 가장 불안했던 부분은 '관리가 힘든 것' 이었어요
- Python을 사용해서 개발자/분석가 접근성이 높은 것은 좋은데,
- 자유도가 너무 높아서 산으로 가더라고요.
예상 독자는 아래와 같아요
- airflow 도입을 고민하는 분
- dag 관리가 산으로 가는 분
- 확산을 해야 하는 분
요약
- 문제: PythonOperator는 관리가 되지 않고, 높은 자유도가 오히려 독이 되고 있음,
- 분석: 재사용 가능한 모듈을 적용해야하고, 모듈은 커밋 전 코드 리뷰가 필요
- 적용: Custom Operator를 적용함
- 결과: 문제 발생 부분이 일원화되고, 반복 코드가 감소함
설명
1. 문제
PythonOperator는 관리가 되지 않고, 높은 자유도가 오히려 독이 되고 있었어요
1-1. 약속되지 않은 data 작업 실행
분명 '대용량 데이터 정리'하는 용도로 도입이 되었는데
모든 반복 작업을 다 넣기 시작했어요.(말도 안하고)
- web service내의 데이터를 업데이트하는 batch
- 사용자에게 mail 보내기
1-2. 아름답지 않은 코드
접근성이 너무 좋아, Python에 익숙하지 않은 분들까지 사용하다보니
아름답지 않은 code들이 난무했어요
- for 문 안에서 connection 맺기
- connection 정보 하드 코딩하기 (url, id, pwd)
- airflow 기능 모두 bypass (jinja template 사용x)
안된다고. 이러면 모두 죽는다고 이야기해도
그럼 "어떻게 수정해야해? 너가 해줘" 가 시전되니
물리적 시간상 적극적으로 대응할 수가 없었어요ㅜ
2. 분석
재사용 가능한 모듈을 적용해야하고, 모듈은 커밋 전 코드 리뷰가 필요하다고 판단했어요
흥분을 가라앉히고 사용자 입장에서 생각해봤어요.
나는 사용자다. 나는 분석가다. 나는 개발자다. 나는 관리자다
나는 사용자다. 나는 분석가다. 나는 개발자다. 나는 관리자다
나는 사용자다. 나는 분석가다. 나는 개발자다. 나는 관리자다
나는 사용자다. 나는 분석가다. 나는 개발자다. 나는 관리자다
Airflow에 넣으면 편하니까 이렇게 사용하는 거라는 결론에 도달했어요
- python 코드 복사 붙여넣기 가능
- crontab은 에러 확인하기 힘들었는데, UI 로 확인 가능
- daemon 띄우지 않고, batch job 실행할 수 있음
- 에러나면 airflow 담당자가 확인해즘
개발자 분들이 말도 안하고 python Operator로 만들어놓고, 결정권자 통해서 이렇게 사용하겠다고
Top down으로 내리면 비루한 데이터 잡부가 아무리 드러누워도
"일단 사용해봅시다."라는 답변이 돌아오고
이게 트리거가 되서 다른 작업도 들어오더라고요.
지금 후회해도 늦었죠ㅜ crontab과 비슷하다고 관리/운영을 간과한 제 잘못이 원인입니다.
- gitlab에 권한을 주지 말았어야 하는데
- python Operator 최소한의 가이드만 주고 오픈하지 말았어야 하는데
안정적인 운영을 위해서 python operator의 자유도를 회수하기로 했어요.(힘들겠지만)
1차 목표는 operator 사용률 python(100%)를 custom(50%)/python(50%) 로 바꾸는거고
그 방법으로는 custom operator를 생각했습니다.
Custom Operator의 장점
- (재사용) '모듈 형식'으로 실행이 가능
- (독립성) 폴더로 업무를 나눌 수 있기 때문에 필요하다면 로직 분리가 가능
- (보안) hook을 이용해 connection을 맺기 때문에, 실수로 다른 IP를 입력할 가능성 배제
TO 관리자: "쿠x, 배x이 이렇게 한데요!"
스터디에서 가장 크게 얻은 부분은 레퍼런스!
dag 단순해지고, 코드 재사용이 많아지고, 에러 원인 확인이 빨라져요
TO 사용자: "님들은 사용만 하시면 됩니다. "
operator들 도입하면, 3자가 만든 것 가져다 사용하면 된다고 어필
aws, postgresql, mysql provider의 예시들이 있어서 사용만 하면 끝나요
3. 적용
Custom Operator를 적용해서 Dag에서는 호출만 하게 했어요.
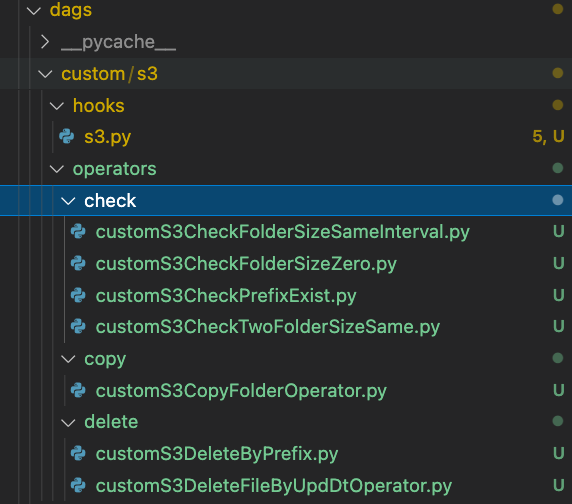
https://github.com/apache/airflow/blob/main/airflow/providers/amazon/aws/operators/s3.py
다양한 operator들이 있지만 그 중에서 s3 operator를 조금 수정해서 사용한 예를 설명할게요
- 원칙적으로는 s3는 폴더가 없지만, 폴더처럼 다루고 싶었어요
- 'apache-airflow-providers-amazon==2.2.0'의 S3Hook은 boto3를 사용하는 걸 확인했어요
- S3Hook을 수정하고, Custom Operator를 만들어 사용하고 있어요
제가 만든 custom operator들은 아래와 같아요
- check용
- customS3CheckFolderSizeSameInterval.py -> 폴더에 data가 insert되는지 확인(before/after 비교라 sensor x)
- customS3CheckFolderSizeZero.py -> 단일 폴더 size가 0인지
- (예시) customS3CheckPrefixExist.py -> list로 폴더 존재 유무 확인
- customS3heckTwoFolderSizeSame.py -> 두개의 폴더 size가 같은지 확인
- copy용
- (예시) customS3CopyFolderOperator.py -> 폴더 기준 복사
- delete용
- customS3DeleteByPrefix.py -> backup 폴더 삭제용
- customS3DeleteFileByUpdDtOperator.py -> 최종 수정 날짜 기준으로 delete(task 로그 삭제용)
3-1. Hook
간단하게 설명하면 hook에 필요한 로직을 다 넣어요
- connection: default
UI에서 생성한 connection을 이용해서, connection_name 만 전달하면 알아서 연결을 해요
s3_hook = S3Hook(aws_conn_id=self.aws_conn_id)
# S3Hook code 중 발췌
(생략)from airflow.providers.amazon.aws.hooks.base_aws import AwsBaseHook
class S3Hook(AwsBaseHook):
conn_type = 's3'
hook_name = 'S3'
def __init__(self, *args, **kwargs) -> None:
(생략)
super().__init__(*args, **kwargs)
(생략)
- logic: check, list, delete, copy 등등
connection을 바탕으로 실행할 logic을 모두 넣어줘요
's3hook.check_for_prefix()'로 실행할 수 있도록요
# s3Hook code 중 발췌
(생략)
@provide_bucket_name
def check_for_prefix(self, prefix: str, delimiter: str, bucket_name: Optional[str] = None) -> bool:
prefix = prefix + delimiter if prefix[-1] != delimiter else prefix
prefix_split = re.split(fr'(\w+[{delimiter}])$', prefix, 1)
previous_level = prefix_split[0]
plist = self.list_prefixes(bucket_name, previous_level, delimiter)
return prefix in plist
(생략)
3-2. Custom Operator
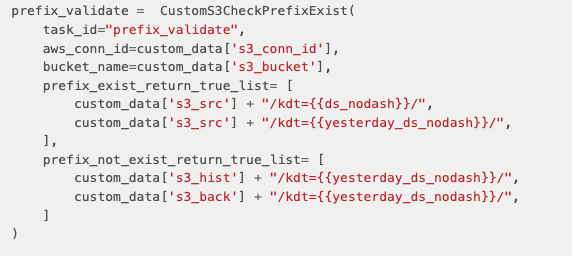
이제 custom opreator를 만들어볼게요 일단 dag에서 호출은 아래처럼 해요.
파라미터는 'prefix 존재해야하는 list' 와 '존재하면 안되는 list' 에요
Operator에서는 connection을 아래처럼 맺고, s3hook 객체에서 logic을 호출해요
s3_hook.check_for_prefix(
bucket_name= self.bucket_name,
delimiter = '/',
prefix = i
)
전체 코드는 아래와 같아요
from typing import TYPE_CHECKING, Dict, List, Optional, Sequence, Union
from airflow.exceptions import AirflowException, AirflowSkipException
from airflow.models import BaseOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
class CustomS3CheckPrefixExist(BaseOperator):
template_fields: Sequence[str] = ('prefix_exist_return_true_list','prefix_not_exist_return_true_list','bucket_name')
ui_color = '#30d6573d'
def __init__(
self,
*,
prefix_exist_return_true_list: list,
prefix_not_exist_return_true_list: list,
bucket_name: Optional[str] = None,
aws_conn_id: str = None,
**kwargs,
):
super().__init__(**kwargs)
self.prefix_exist_return_true_list = prefix_exist_return_true_list
self.prefix_not_exist_return_true_list = prefix_not_exist_return_true_list
self.bucket_name = bucket_name
self.aws_conn_id = aws_conn_id
def execute(self, context: 'Context'):
s3_hook = S3Hook(aws_conn_id=self.aws_conn_id)
for i in self.prefix_exist_return_true_list:
if (s3_hook.check_for_prefix(bucket_name= self.bucket_name, delimiter = '/', prefix = i)):
self.log.info(f'should exist, correct = prefix exists : {i}')
continue
else:
raise Exception(f'should exist, incorrect = prefix not exists : {i} \n please check the folder')
for j in self.prefix_not_exist_return_true_list:
if not (s3_hook.check_for_prefix(bucket_name = self.bucket_name, delimiter = '/', prefix = j):
self.log.info(f'should not exist, correct = prefix not exist : {j}')
continue
else:
raise Exception(f'should not exist, incorrect = prefix exists : {j} \n please check the folder')
raise AirflowSkipException
3-3. Custom Hook
BaseAwsConnection = TypeVar("BaseAwsConnection", bound=Union[boto3.client, boto3.resource])
class BaseSessionFactory(LoggingMixin)
링크: https://github.com/apache/airflow/blob/main/airflow/providers/amazon/aws/hooks/base_aws.py
저는 prefix로 복사하는 operator를 아래처럼 만들었어요
# custom.s3.hooks.customS3Hook
def customS3CopyFolder(
self, source_bucket_name, source_bucket_key_prefix, dest_bucket_name, dest_bucket_key_prefix
) -> None:
self.log.info("=custom s3=")
dest_bucket = self.get_bucket(dest_bucket_name)
for old_key in self.list_keys(bucket_name=source_bucket_name, prefix=source_bucket_key_prefix):
old_source = {'Bucket': source_bucket_name, 'Key': old_key}
new_key = old_key.replace(source_bucket_key_prefix, dest_bucket_key_prefix, 1)
new_obj = dest_bucket.Object(new_key)
new_obj.copy(old_source)
#self.log.info(f"copy {old_source} -> {new_key}")
실행은 아래처럼 하고 있어요,

4. 결과
문제 발생 부분이 일원화되고, 반복 코드가 감소했어요
너무 좋은데 러닝 커브가 있다는게 단점이에요.
그리고 custom operator 만들어달라는 요구가 들어오는 것도 무서워요.
'우리팀만' 사용하면 airflow 2.0의 taskflow api로 멋있게 만들겠지만
구축 후 운영을 고려한다면 python operator 보다는 custom operator만 오픈하는 것을 추천합니다.
이전 글에는 'task 분리' 에 대해서 이야기했는데
https://mightytedkim.tistory.com/121
Airflow) 'Task 분리' 실무 적용하기 _k8s/spark
2022.05~07, 3달동안 진행한 airflow 스터디를 끝내고 실무에 적용한 내용 일부를 정리햇어요 airflow를 운영하면서 가장 불편했던 부분은 'Task가 분리되지 않은 것' 이었어요 어디서 문제가 생겼는지
mightytedkim.tistory.com
다음 글에서는 BEST Practice를 얼마나 무시하고 사용했는지에 대해 이야기해보려해요
(스포)
date.today() -> execution_date
connection 정보 직접 입력 -> conn_id
하나의 task에 하나의 작업만(원자성) -> task 분리
다시 실행해도 결과 같아야(멱등성) -> 데이터 클렌징, 백업
전역 변수 제거 -> task 독립성 훼손 및 scheduling check마다 실행
'Data > Airflow' 카테고리의 다른 글
| Airflow) Base image에 라이브러리 추가하기 (0) | 2023.04.23 |
|---|---|
| airflow) dag clear 하지 않고 특정 시점부터 재시작하기 (0) | 2023.02.27 |
| Slipp) Airflow 2.0 스터디 후기_22기 (0) | 2022.07.29 |
| 글또) 7기 다짐글(2022.05 ~ 2022.11)_airflow (0) | 2022.07.10 |
| Airflow) 'Task 분리' 실무 적용하기 _k8s/spark (0) | 2022.07.04 |