Model의 동적 배포를 위해서, FaaS를 도입한 이야기를 적어봤습니다.
글의 구조는 아래와 같습니다.
- Nuclio가 무엇인가요?
- 왜 굳이 Nuclio인가요?
- CVAT과 어떻게 연동을 하나요?
.
글의 타깃 독자는 아래와 같습니다.
- Nuclio(FaaS)에 대해 궁금하신 분
- Vision ML 인퍼런싱을 고려하는 분
- CVAT을 사용하시는 분
지난 포스팅에서는 아래 2가지를 적었고
- Vision MLOps 프로젝트 투입: https://mightytedkim.tistory.com/205
- 라벨링 툴로 CVAT을 선택한 이유: https://mightytedkim.tistory.com/206
이번에는 `동적 모델링`을 위해 ‘FaaS’인 ‘Nuclio’를 도입한 내용을 적었어요.
1. Nuclio가 뭐에요?
nuclio는 FaaS 툴이에요. (보통 aws lambda로 FaaS에 많이들 익숙하실거에요)

제가 생각한 장점은 다음과 같아요
- 가벼움 (DB도 없음)
- 트리거 많음(http, kafka, grpc)
- 성능 좋음 (event 처리 초당 400,000)
- 연계 많음 (Kubeflow, Jupyter, CVAT, MLRun, Loki)

단점은 하나에요.
- 레퍼런스가 별로 없어요
하지만!! 제가 대신 삽질을 했습니다.

개발자한테 궁금한거는 slack으로 물어보며 진행했어요 ㅎ
2. 왜 굳이 Nuclio인가요?
저 같은 경우 model inferencing을 위해 여러 툴들을 검토했어요.
BentoML, FastAPI 를 고려하다가 BentoML로 거의 기울었는데,
`오픈소스 갯수 최소화` 라는 요구사항이 들어와서 좀 더 가벼운 Nuclio를 선택했어요.
어짜피 CVAT을 라벨링 툴로 선택했으니, 연계가 쉬운 Nuclio가 더 좋기도 하고요.
Nuclio는 DB도 없이, 아래 명령어 하나면 끝이에요.
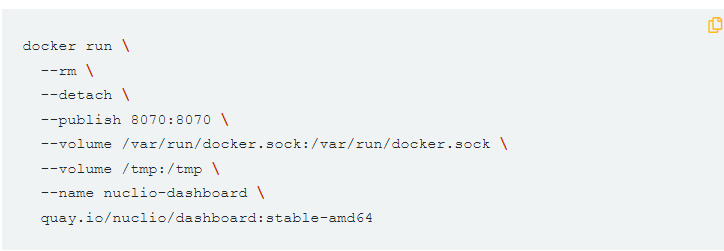
구조는 dashboard가 일종의 operator가 되어서 docker나 k8s에 대신 container를 실행해줘요.
이렇게 실행된 container는 아래의 ` Nuclio Processor `에요.
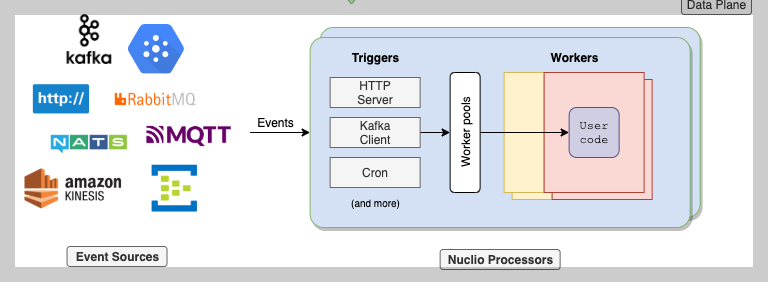
Nuclio Processor를 조금 더 볼게요. Trigger와 worker가 있어요.
Trigger는 뭔가 Event 처리하는 것 같고, Worker는 `worker pools` 라는게 나오죠?
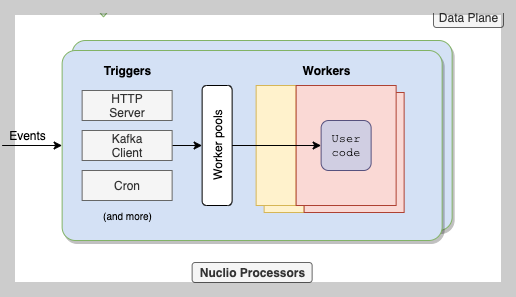
Trigger는 event를 받아요. http를 예로 들어볼게요.
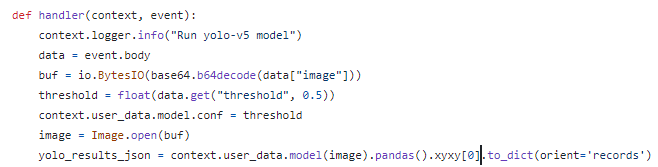
아래 코드는 'Segment Anything Model' 을 인퍼런싱하는 코드에요.
handler 함수의 event 파라미터를 넘겨받는게 끝이에요.
이제 Worker를 보죠. 예를 들어 제가 worker 최댓값을 4로 설정하면 이렇게 pool이 생겨요
root@03d88a37705a:/opt/nuclio# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 12:47 ? 00:00:00 processor
root 32 1 2 12:47 ? 00:00:03 /usr/bin/python3 -u /opt/nuclio/_nuclio_wrapper.py --handler main:handler --socket-path /tmp/nuclio-rpc-co4lmibossh000ep38c0.sock --platform-kind local --namespace nuclio --wo
root 33 1 2 12:47 ? 00:00:03 /usr/bin/python3 -u /opt/nuclio/_nuclio_wrapper.py --handler main:handler --socket-path /tmp/nuclio-rpc-co4lmibossh000ep38d0.sock --platform-kind local --namespace nuclio --wo
root 34 1 2 12:47 ? 00:00:03 /usr/bin/python3 -u /opt/nuclio/_nuclio_wrapper.py --handler main:handler --socket-path /tmp/nuclio-rpc-co4lmibossh000ep38dg.sock --platform-kind local --namespace nuclio --wo
root 35 1 2 12:47 ? 00:00:03 /usr/bin/python3 -u /opt/nuclio/_nuclio_wrapper.py --handler main:handler --socket-path /tmp/nuclio-rpc-co4lmibossh000ep38cg.sock --platform-kind local --namespace nuclio --wo
root 1395 0 0 12:49 pts/0 00:00:00 bash
root 1426 1395 0 12:49 pts/0 00:00:00 ps -ef
worker 설정 변경은 script에서 할 수도 있고, ui에서 할 수도 있어요

그래서 worker가 왜 좋냐. container로 뜨면 tmux 처럼 session이 나눠져있으니 바로 처리해서 응답을 줄 수 있어요.
초당 400,000개까지 가능하고 실제로 실시간 인퍼런싱에 많이 사용이 된다고 해요.

어떻게 사용되는지 간단한 예시로 설명할게요
Nuclio Processor 가 이미 container로 실행 중이고, 이미지의 좌표들을 받을거에요
Nuclio function response: [
{"confidence": 0.8961721062660217, "label": "person", "points": [671.7879028320312, 395.37213134765625, 810.0, 878.361328125], "type": "rectangle"},
{"confidence": 0.8702478408813477, "label": "person", "points": [220.6570587158203, 408.1410217285156, 346.1673278808594, 867.3811645507812], "type": "rectangle"},
{"confidence": 0.8515626788139343, "label": "person", "points": [49.2508430480957, 389.99053955078125, 248.07818603515625, 912.4585571289062], "type": "rectangle"},
{"confidence": 0.8493338227272034, "label": "bus", "points": [12.65086841583252, 223.37843322753906, 809.7070922851562, 788.5164794921875], "type": "rectangle"},
{"confidence": 0.534941554069519, "label": "person", "points": [0.04542803764343262, 552.4113159179688, 67.88233184814453, 875.3746337890625], "type": "rectangle"}
]
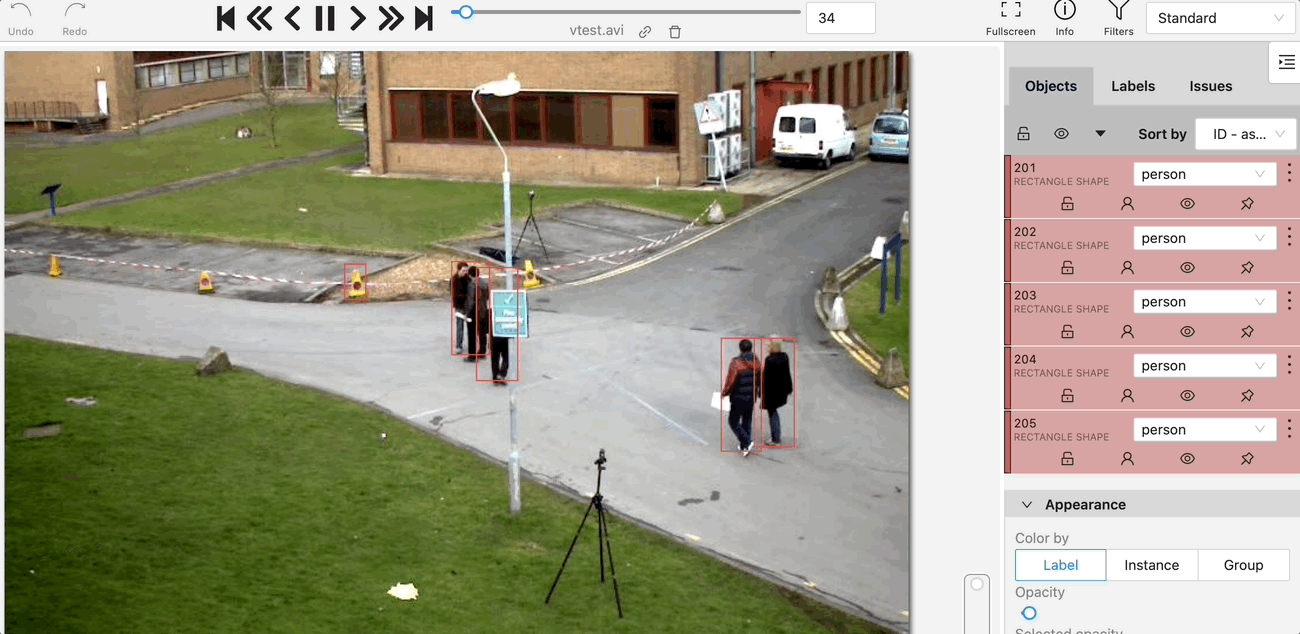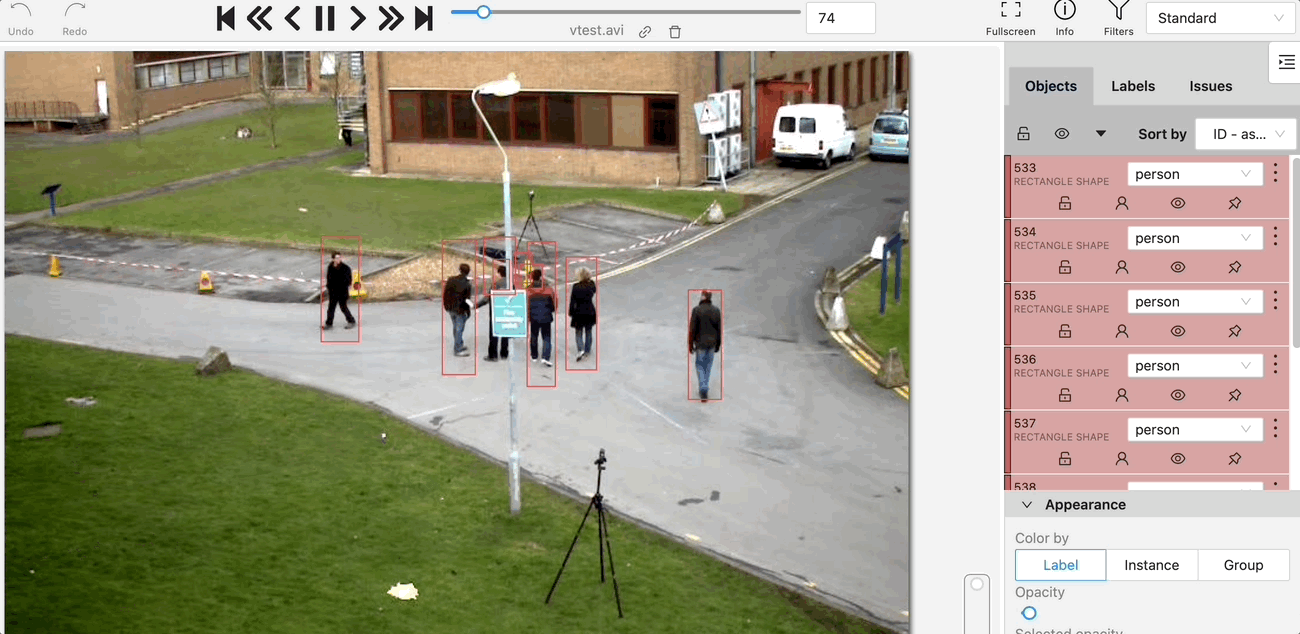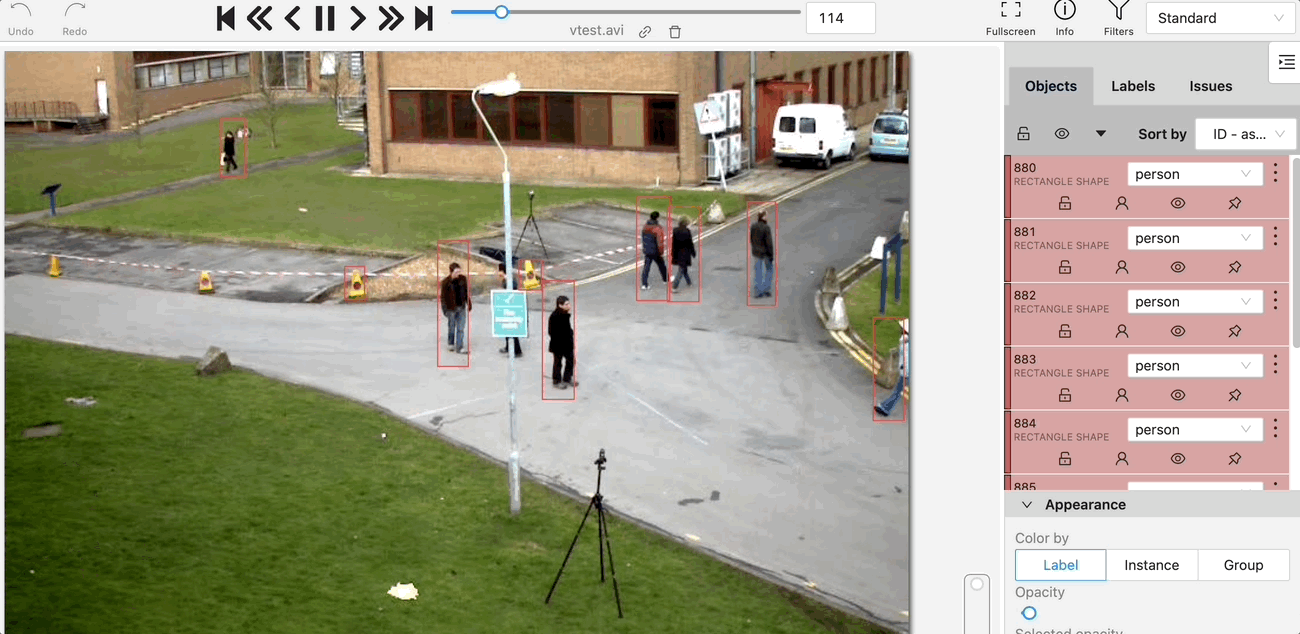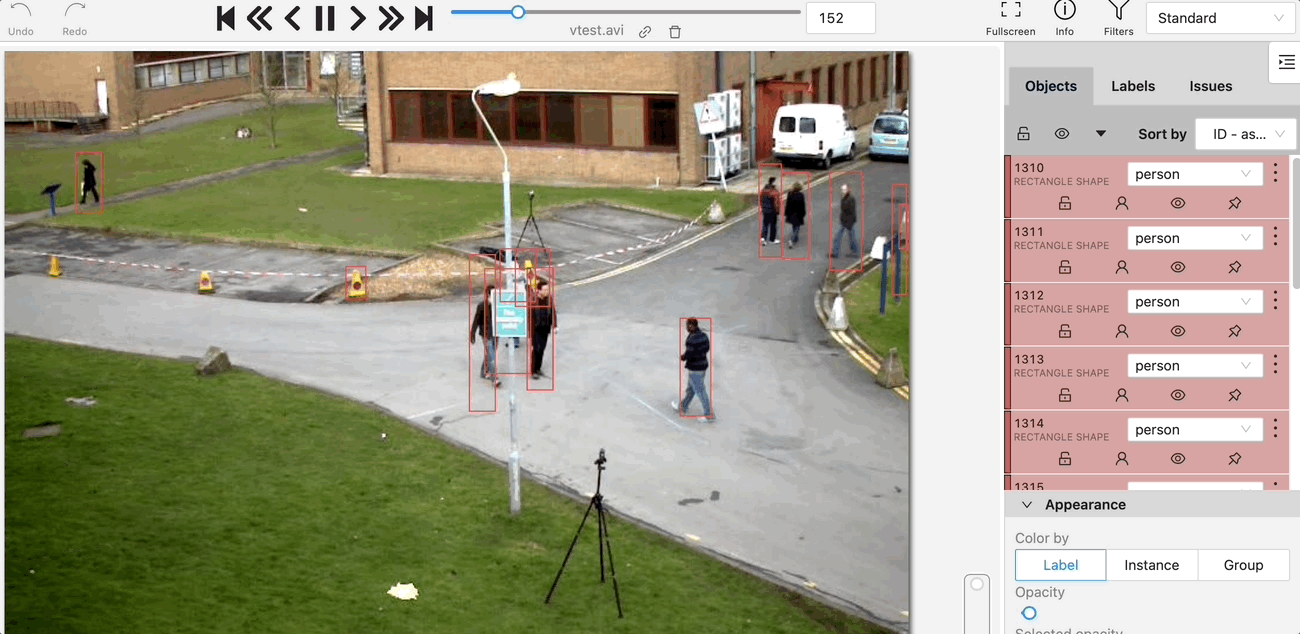
좌표를 이미지에 뿌리면 아래 그림처럼 나올거고요.
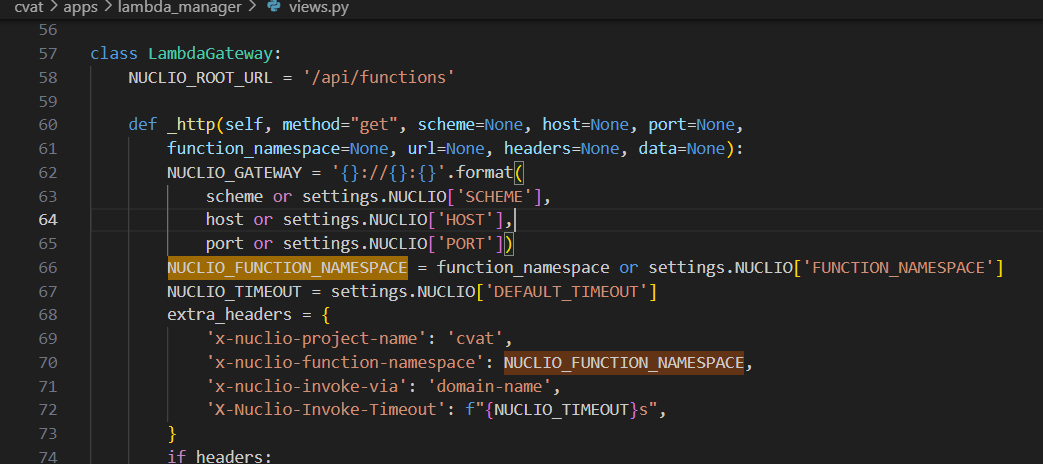
샘플 코드에요.
import requests
import base64
import json
# 1. URL of the Nuclio function's HTTP trigger endpoint
## 32768 포트에 nuclio processor가 떠있다고 가정하고, endpoint를 설정해줘요
nuclio_endpoint_url = "http://192.168.219.***:32768"
# 2. Read the binary image data from a file
## image를 읽어서 base64로 만들어줘요
## nuclio processor에서 'image' key 를 읽어서 base64 decode 하도록 코드 짜놨어요. (취향)
with open('bus.jpg', 'rb') as image_file:
image_binary = image_file.read()
# Encode the binary image data to base64
image_base64 = base64.b64encode(image_binary).decode('utf-8')
data = {'image': image_base64}
# 3. Send the binary image data as part of the POST request
## api 요청을 보냅니다.
response = requests.get(nuclio_endpoint_url, data=json.dumps(data), headers={"Content-Type": "application/json"})
# 4. Check the response
## 받고 확인해요
if response.status_code == 200:
result = response.text # Assuming the function returns a response
print(f"Nuclio function response: {result}")
else:
print(f"Error: {response.status_code}, {response.text}")
nuclio관련 하고 싶은 말은 진짜 많은데... 글이 더 길어질 것 같아서 다음글에서 정리할게요.
3. CVAT과 어떻게 연동을 하나요?
그래서 nuclio가 가볍고, 병렬처리 되는건 알겠는데 cvat과는 어떤 관계일까요.
https://github.com/opencv/cvat/tree/develop/cvat/apps
이걸 알기 위해서는 cvat 코드를 뜯어봐야해요.
여기도 AWS Lambda가 FaaS인 것처럼 LambdaGateway 라는 class를 사용해요.
cvat/apps/lambda_manager/views.py
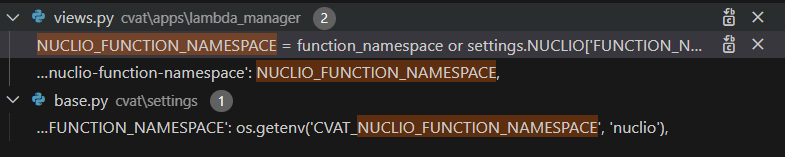
기본 namespace는 `nuclio`기 때문에 k8s 사용하시는 분들은 그냥 nuclio 명칭 사용하시면 되요.
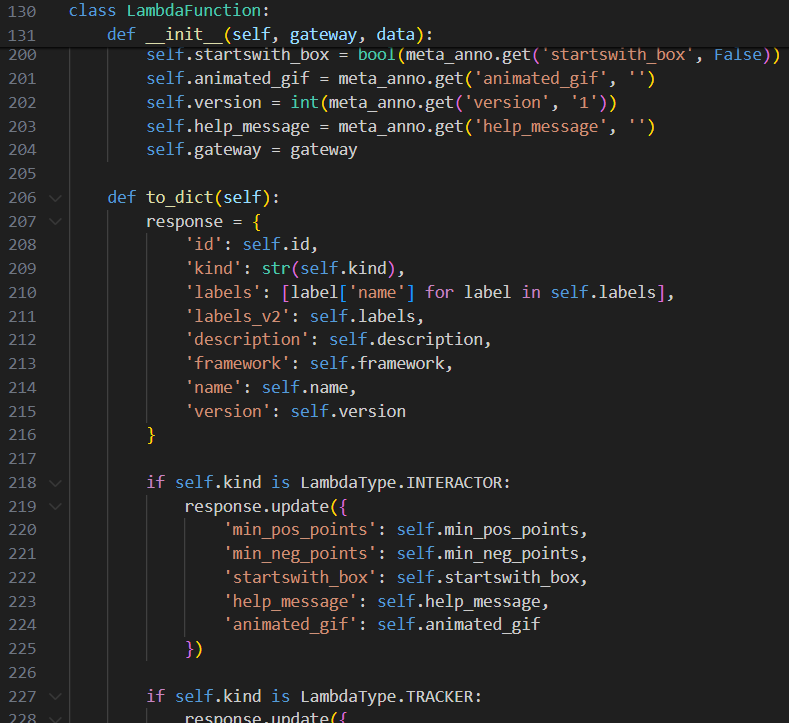
LambdaFunction 클래스는 응답을 받아서 cvat에 맞게 형식을 맞춰줍니다.
그러면 이런식으로 cvat에서 FaaS인 nuclio를 사용할 수 있어요!
실제 예시에요
Interactor라는 형식을 이용해, Facebook의 SAM(Segment Anything Model)
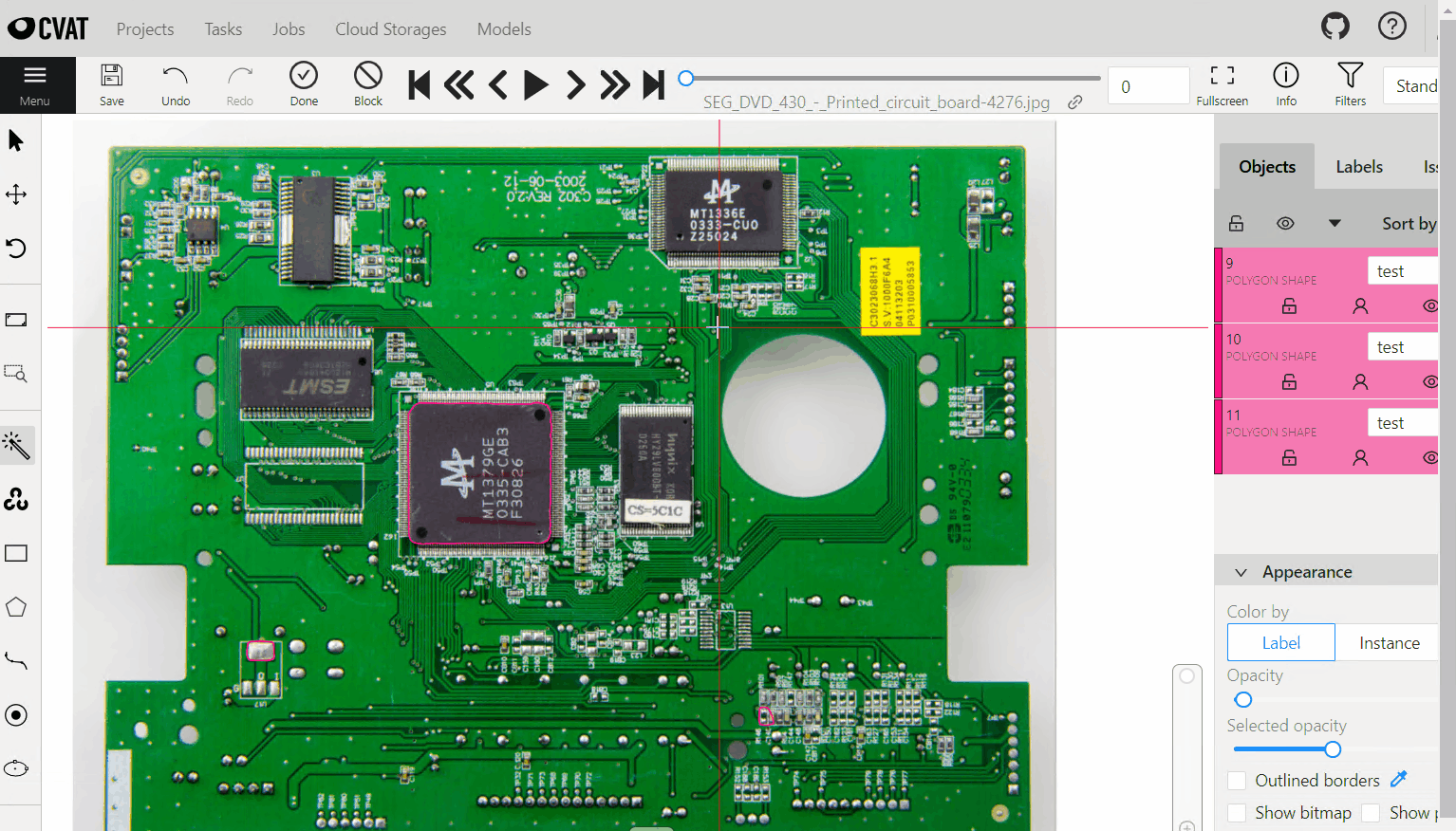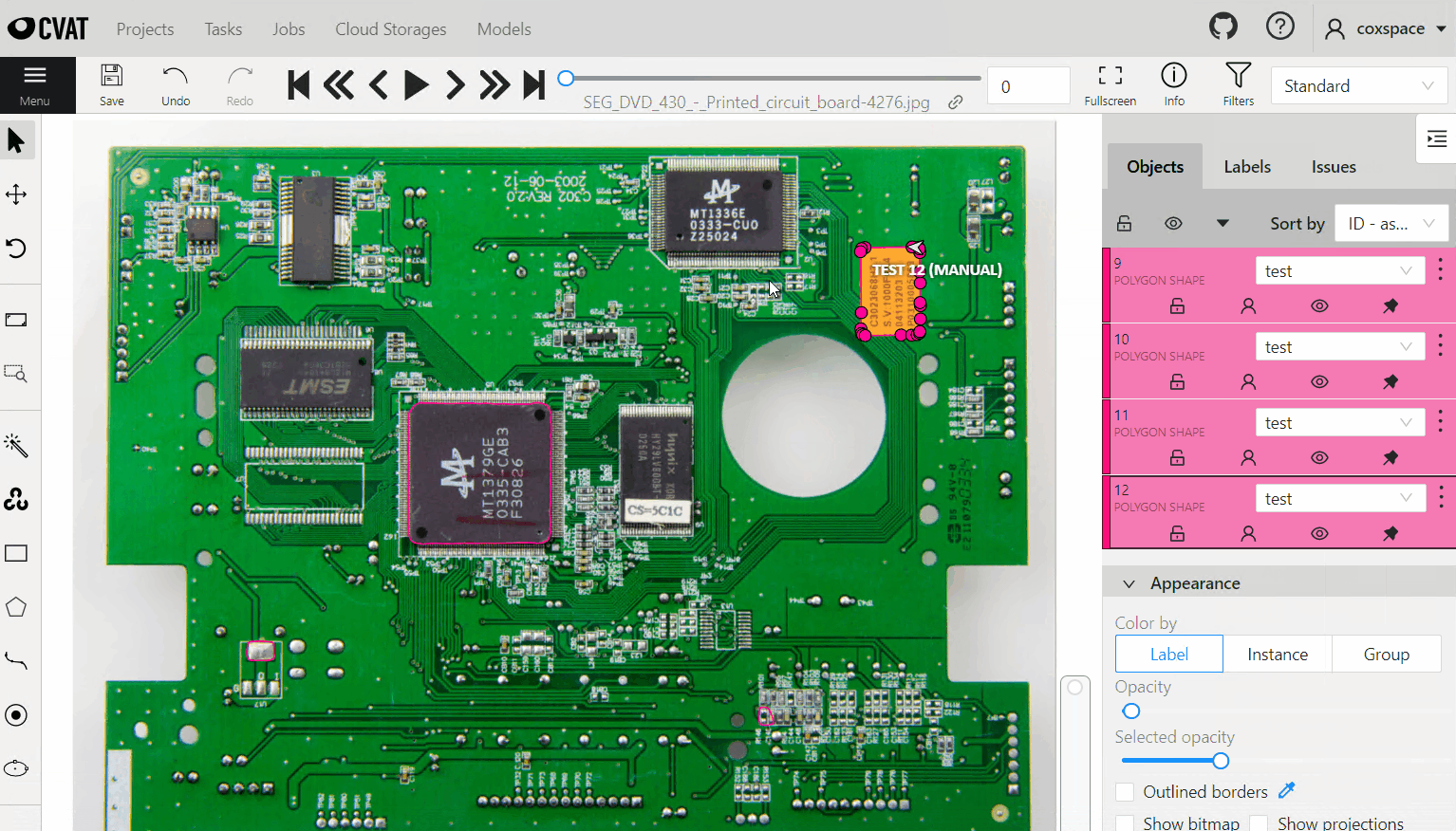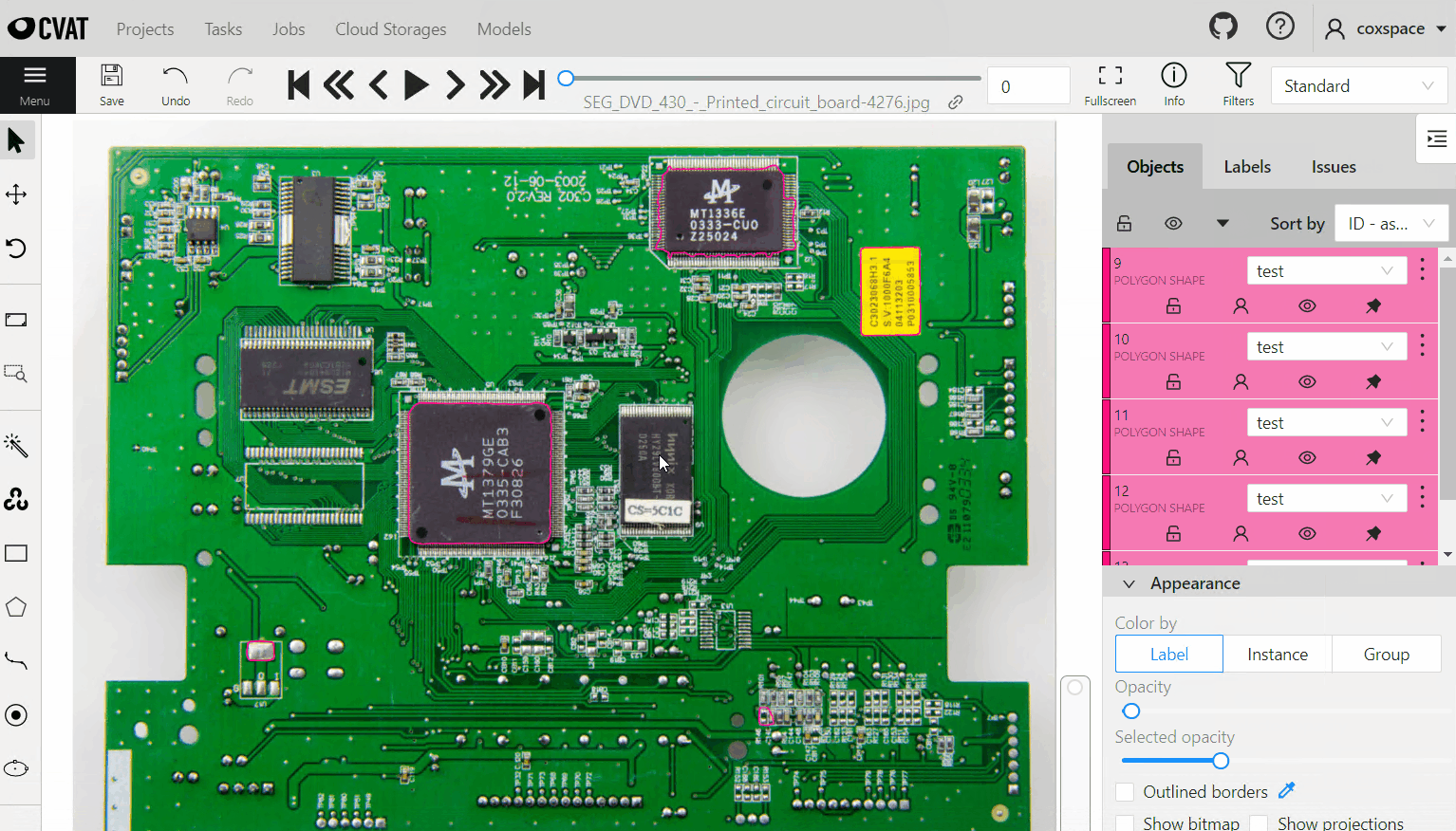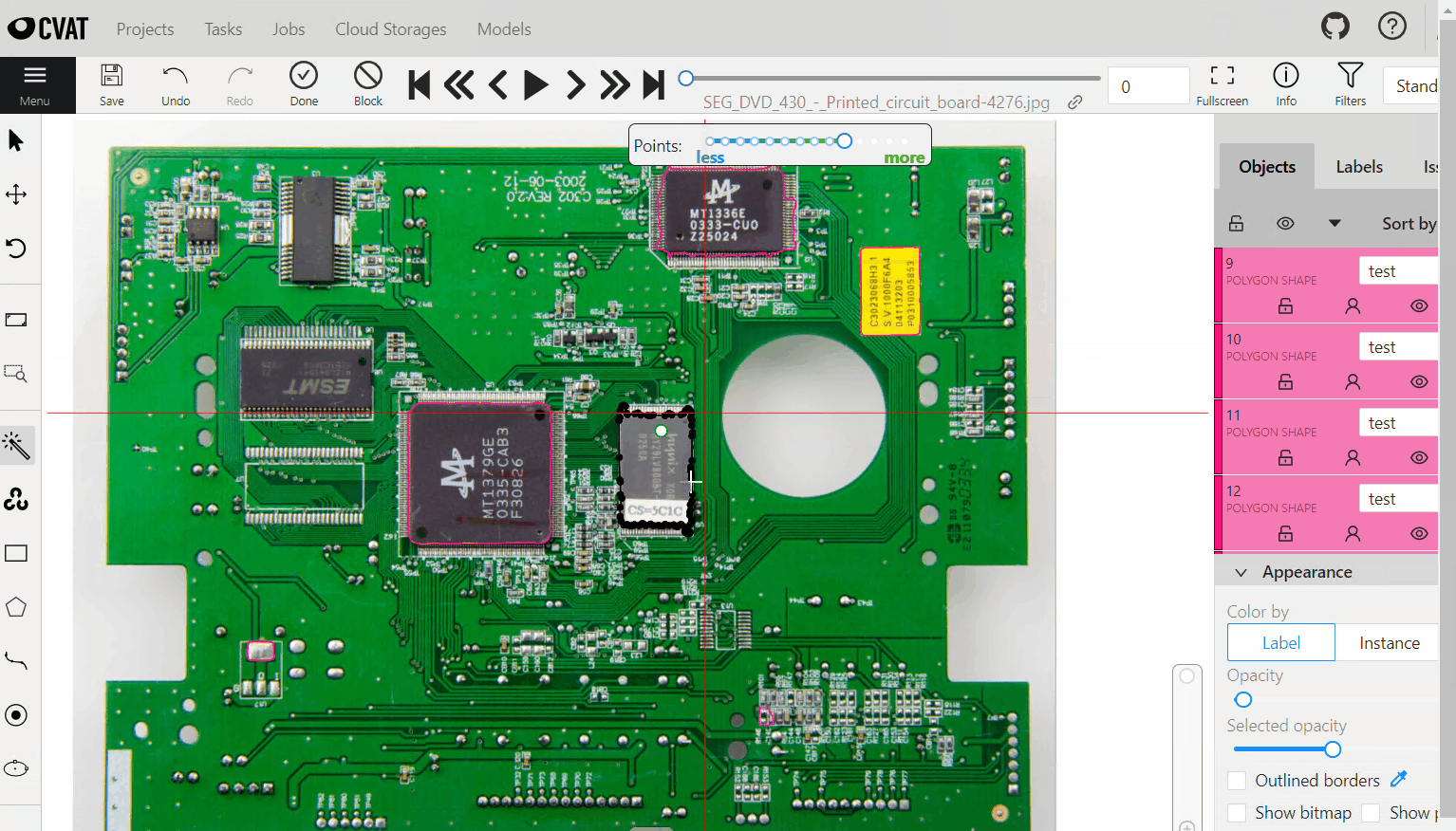
Detector를 이용한 object detection
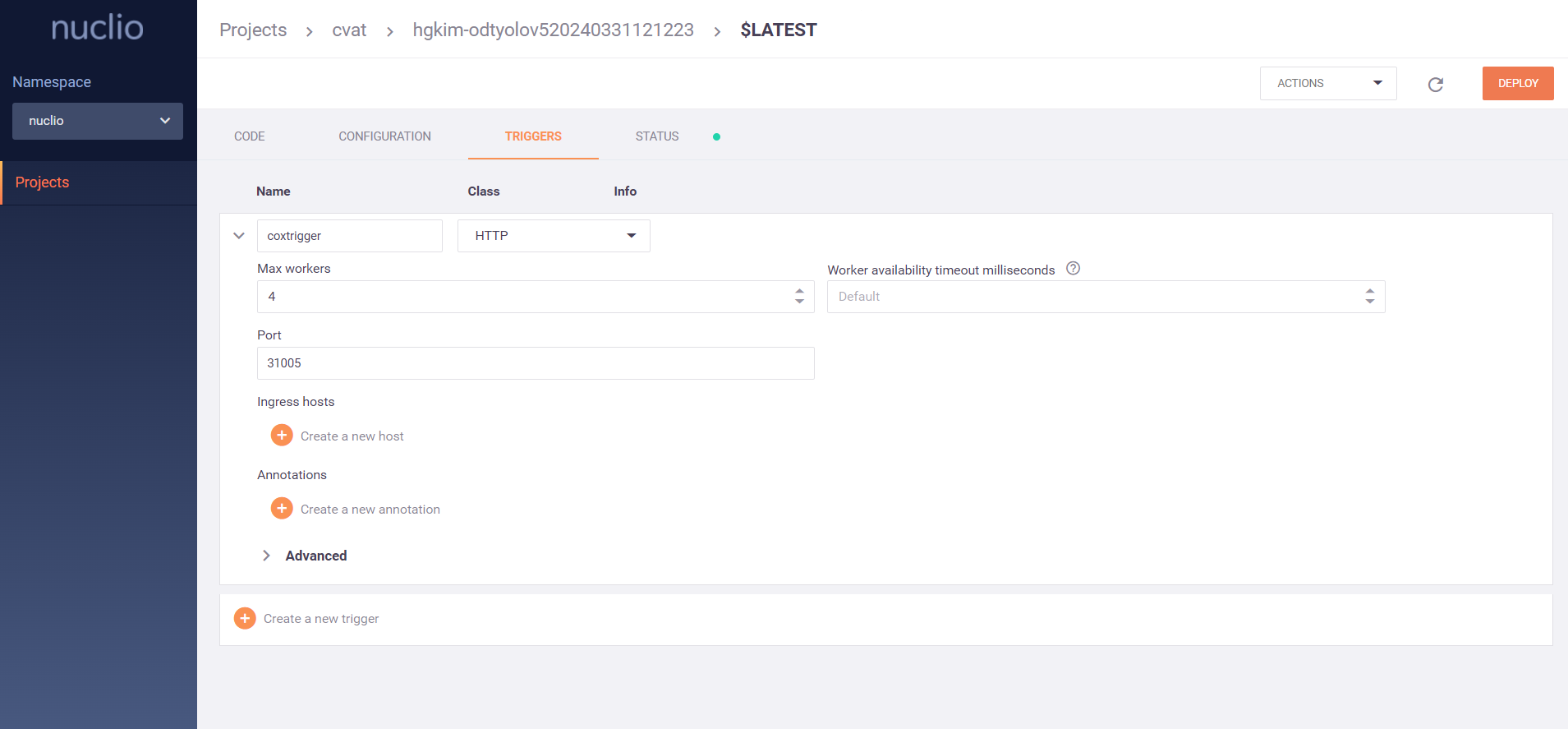
모델은 pod 형태로 배포되고, 관리 페이지에서 설정값을 조절 할 수 있답니다. ㅎ

마무리
오늘도 혼자 신나서 쓰다가 너무 많이 쓴게 아닐까 싶네요.
그래도 Nuclio 관련 한글 내용은 90%가 다 hello world여서,
실제 사용해본 경험을 공유하는 건 의미가 있을 거라고 생각해요,
nuclio는 loki로 로그도 연결할 수 있고, autoscaling도 됩니다.
jupyter를 이용해 배포할 수 있고 kfp 버전만 맞다면 MLRun이라는 툴과 연계도 가능해요.
다음 글은 CVAT과 Nuclio를 이용해 라벨링부터 학습까지 연결했는지 적어볼게요 :)
'AI > MLOps' 카테고리의 다른 글
| 데이터 잡부의 MLOps도전기 (4) - 모델 배포를 위해 FaaS를 실행해보자_Nuclio (3) | 2024.04.28 |
|---|---|
| 데이터 잡부의 MLOps도전기 (2) - 라벨링 툴로 CVAT을 선택한 이유 #VISION (0) | 2024.01.21 |
| 데이터 잡부의 MLOps도전기 (1) #이미지 불량탐지 (6) | 2024.01.07 |
| Bentoml) Yatai 1.0 에서 무엇이 바뀌었을까 (0) | 2022.10.10 |
| Mlflow) python, airflow로 테스트해보기 (0) | 2022.06.26 |