
요약
1. kubenetes 환경에서 airflow를 이용해 spark_submit을 함
2. SparkKubernetesOpertor(SKO)를 선택함
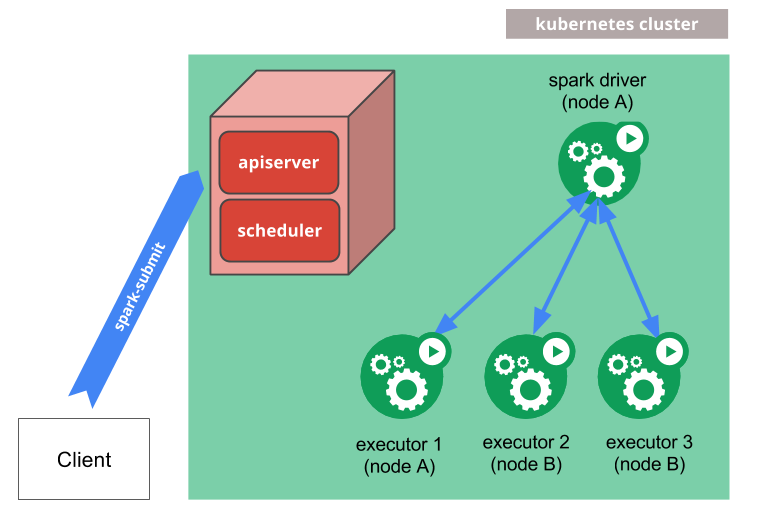
개요
- 상황
- 쿠버네티스 클러스터 환경에서 spark_submit 관리 필요
- 후보 (3가지)
- KubernetePodOperator(KPO) : dag
- SparkApplication(CRD) : yaml
- SparkKubernetesOperator(SKO) : yaml + dag
- 최종 결과 (SKO)
- command
- script/scample/sample-sko-spark.yaml
- dags/sample/sample-sko-spark.py
- 시행착오 (FYI)
- SKO) role 권한 때문에 Forbidden 에러
- SKO) sensor의 task_id 때문에 에러
- SKO) application_file 읽기 버그
상황
쿠버네티스 클러스터 환경에서 spark_submit을 관리하는 방법이 필요했어요
Airflow에서 대용량 작업을 할 때는 spark를 써야하기 때문이에요.
Don't Use Airflow as a Processing Framework
Conversely, Airflow was not designed to be a processing framework. Since DAGs are written in Python, it can be tempting to make use of data processing libraries like Pandas. However, processing large amounts of data within your Airflow tasks does not scale and should only be used in cases where the data are limited in size. A better option for scalability is to offload any heavy duty processing to a framework like Apache Spark, then use Airflow to orchestrate those jobs.
출처: https://www.astronomer.io/guides/dag-best-practices
후보
3가지 대안이 있었는데, 그 중에서 spark on Kubernetes를 선택했어요
1. KubernetesPodOperator(KPO), dag
instance를 여러개 할당해도 pod가 1개만 동작하는 것을 보고, 적합하지 않다고 판단
가장 먼저 고민했던거는 `POD안에서 local로 spark_submit`을 하는 방법이에요.
spark에 특화된 것은 아니고, airflow에서 POD를 생성하는 방식을 이용했어요.
# `--spark.driver.host = localhost`지정하지 않으면,
# pod의 이름을 host가 따라가면서 syntax error가 나옴
KubernetesPodOperator(
task_id='sample-kpo-spark-task',
name='sample-kpo-spark-nm',
namespace='airflow',
image='private-reop/test/spark-3.1.2-util-sample:1.1.1',
cmds=['/opt/spark/bin/spark-submit'],
arguments=[
'--master','local',
'--name','spark-name1',
'--conf','spark.driver.host=localhost',
'/app/main.py'
],
in_cluster=True,
config_file=None,
is_delete_operator_pod=False,
get_logs=True,
dag=dag
)
장점
- 특정 작업에 종속적이지 않음
- airflow 기본적인
단점
- pod안에서 local로 돌아야하니까, 부하가 큰 작업에 적합하지 않음
- 독립적인 pod에 executor를 만들 수 없음
관련해서는 아래 포스팅에 더 설명했어요.
https://mightytedkim.tistory.com/40?category=928713
Airflow) kuberentesPodOperator 설정_helm,logging,git-sync
airlow 1.10 부터 적용되고, airflow 2.0에서 본격적으로 사용되는 KPO 자료가 없어서 2주간의 삽질기 ㅎㅎ 아 진짜 쫄깃 쫄깃하고, 안되서 도중에 argo를 파야하나 생각하고 휴.. 요약 airflow는 airbnb에서
mightytedkim.tistory.com
2. SparkApplication, yaml
crd로 정의된 sparkapplication 활용
sparkapplication(crd)을 이용하기로 했어요.
sparkapplication은 `spark_submit 프로세스`에서 operator가 하나 추가되요
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: "sample-sparkapplication" #custom
namespace: "default"
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "private-repo/test/spark-3.1.2-util-sample:1.1.1" #custom
imagePullPolicy: Always
mainApplicationFile: local:///app/main.py #custom
sparkVersion: "3.1.2"
restartPolicy:
type: Never
driver:
cores: 1
coreLimit: "1024m"
memory: "512m"
labels:
version: 3.1.2
serviceAccount: sparkoperator-spark-operator # sa
executor:
cores: 1
instances: 2 #instance 늘려봄
memory: "512m"
labels:
version: 3.1.2
~
sparkoperator의 역할
1. namespace별로 sparkapplication이 실행되는 것을 확인
2. driver가 실행되도록 명령합니다.
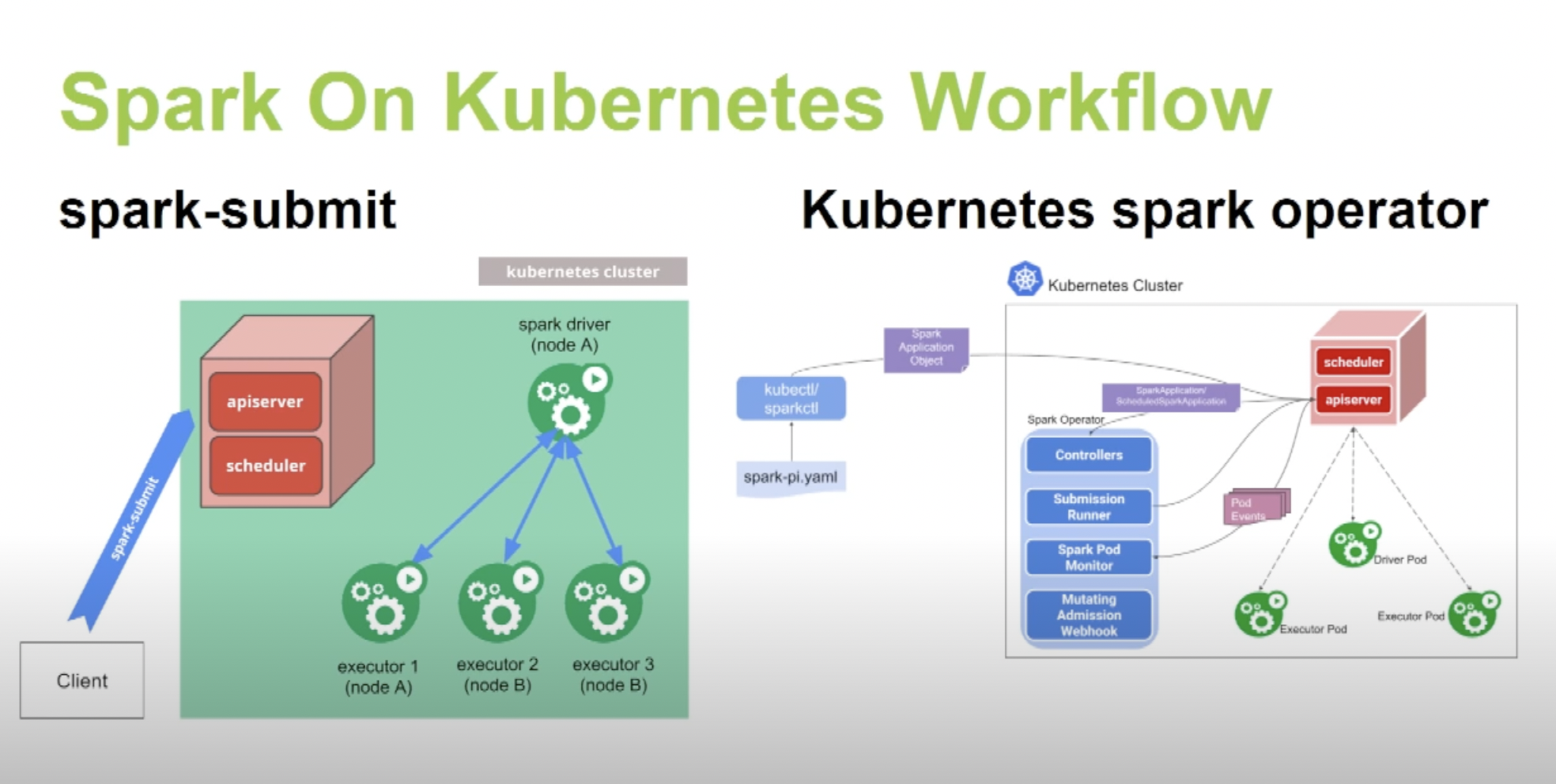
위 그림에서 sparkoperator만 추가되는데 command로 보면 아래와 같아요.
spark operator를 미리 띄워놓고, sparkapplication을 생성하면 driver가 실행되는 구조에요.
command
| # sparkoperator(POD) 미리 생성 $ k get pod | grep sparkoperator sparkoperator-spark-operator-545446bf55-q5v9x 1/1 Running 0 2d22h ----------------------------------------------- # sparkapplcation(CRD) 생성 $ k apply -f 3_spark-test.yaml sparkapplication.sparkoperator.k8s.io/spark-test created ## Sparkapplication -> Sparkoperator $ k logs sparkoperator-spark-operator-545446bf55-q5v9x (생략) to: { "sparkApplicationId": "spark-974b588858c2443da6fabb80beeaea12", "submissionID": "16bde48b-5b20-4834-9191-cebbeeb2306e", "lastSubmissionAttemptTime": "2021-11-25T01:03:06Z", "terminationTime": null, "driverInfo": { "webUIServiceName": "spark-test-ui-svc", "webUIPort": 4040, "webUIAddress": "10***.4.***:4040", "podName": "spark-test-driver" }, "applicationState": { "state": "RUNNING" }, "executorState": { "spark-test-2b6f487d549e3a2b-exec-1": "RUNNING", "spark-test-2b6f487d549e3a2b-exec-2": "RUNNING" }, "executionAttempts": 1, "submissionAttempts": 1 } (생략) ## Sparkoperator -> Driver $ k get pod | grep test spark-test-driver 1/1 Running 0 15s ## Driver -> Executor $ k get pod | grep test spark-test-5aa0187d54991981-exec-1 1/1 Running 0 15s spark-test-5aa0187d54991981-exec-2 1/1 Running 0 15s spark-test-driver 1/1 Running 0 28s ## Complete $ k get pod | grep test spark-test-driver 0/1 Completed 0 89s |
이제 sparkapplication이 instance 별로 executor를 만들어주는 친구라는 걸 알았어요.
sparkapplication 관련해서는 아래 포스팅에서 hello-world를 했어요
https://mightytedkim.tistory.com/28?category=922753
Kubernetes) How to run Spark with Minio in Kubernetes_2
이전 게시물에서는 kuberenetes 없이 python으로 minio의 결과를 확인해봤어요 pyenv > spark-submit 로 " data-og-host="mightytedkim.tistory.com" data-og-source-url="https://mightytedkim.tistory.com/27?ca..
mightytedkim.tistory.com
yaml을 매번 실행 할 수는 없으니까, 관리를 생각해야 했어요.
3. sparkOnKubernetes, yaml + dag
argo도 있었지만, 사용자 선호도가 높은 airflow를 선택했어요.
# application_file관련 버그 : https://github.com/apache/airflow/issues/17371
SparkKubernetesOperator(
task_id='task1-spark',
namespace="default",
application_file=open("/opt/airflow/dags/repo/script/sample/sample-sko-spark.yaml").read_text(), #officially know bug
kubernetes_conn_id="kubeConnTest", #ns default in airflow connection UI
do_xcom_push=True,
dag=dag
)아직은 incubating 단계라 자료가 진짜 없어서,, 삽질 엄청했네요ㅜㅜ
-----------------------------------------
+ 20220812
kubeConnTest는 airflow connection이고
===============================
Conn Id kubeConnTest
Conn Type Kubernetes Cluster Connection
In cluster configuration (check)
Namespace (spark-operator가 배포되어 있는 ns)
===============================
예시는 default에 했지만, 운영에는 저도 다른 ns를 명시했습니다.
-----------------------------------------
최종 결과
실제 코드와 실행하는 방법에 대해 정리했어요.
command
| $ k get pod | grep sko sample-sko-spark-20211125t012827-1-driver 1/1 Running 0 26s sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-1 1/1 Running 0 14s sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-2 1/1 Running 0 14s sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-3 1/1 Running 0 14s $ k get pod -n airflow | grep log sampleskosparksampleskosparklog.7d21881b74bd4c3180d8a470ff4257a5 1/1 Running 0 42s |
dags/sample/sample-sko-spark.py
| """ This is an example DAG which uses SparkKubernetesOperator and SparkKubernetesSensor. In this example, we create two tasks which execute sequentially. The first task is to submit sparkApplication on Kubernetes cluster(the example uses spark-pi application). and the second task is to check the final state of the sparkApplication that submitted in the first state. Spark-on-k8s operator is required to be already installed on Kubernetes https://github.com/GoogleCloudPlatform/spark-on-k8s-operator """ from datetime import datetime, timedelta # [START import_module] # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.operators.dummy_operator import DummyOperator from airflow.providers.cncf.kubernetes.operators.spark_kubernetes import SparkKubernetesOperator from airflow.providers.cncf.kubernetes.sensors.spark_kubernetes import SparkKubernetesSensor #etc import pathlib # [END import_module] # [START instantiate_dag] dag = DAG( 'sample-sko-spark', default_args={'max_active_runs': 1}, description='submit spark-pi as sparkApplication on kubernetes', schedule_interval=timedelta(days=1), start_date=datetime(2021, 1, 1), catchup=False, tags=['sample','hgkim'] ) ############################ # Pod ############################ # $ k get pod | grep sko # sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-1 1/1 Running 0 14s # sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-2 1/1 Running 0 14s # sample-sko-spark-20211125t012827-1-5bd3597d54b5a9d4-exec-3 1/1 Running 0 14s # sample-sko-spark-20211125t012827-1-driver 1/1 Running 0 26s t1 = SparkKubernetesOperator( task_id='task1-spark', namespace="default", application_file=pathlib.Path("/opt/airflow/dags/repo/script/sample/sample-sko-spark.yaml").read_text(), #officially know bug kubernetes_conn_id="kubeConnTest", #ns default in airflow connection UI do_xcom_push=True, dag=dag ) ############################ # logs ############################ # saving log from executors # $ k get pod -n airflow | grep log # sampleskosparksampleskosparklog.7d21881b74bd4c3180d8a470ff4257a5 1/1 Running 0 42s t2 = SparkKubernetesSensor( task_id='sample-sko-spark-log', namespace="default", application_name="{{ task_instance.xcom_pull(task_ids='task1-spark')['metadata']['name'] }}", kubernetes_conn_id="kubeConnTest",#ns default in airflow connection UI attach_log=True, # dag=dag, ) t1 >> t2 |
script/scample/sample-sko-spark.yaml
| apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: "sparkapp-test-{{ ts_nodash|lower }}-{{ task_instance.try_number }} #custom namespace: "default" spec: type: Python pythonVersion: "3" mode: cluster image: "private-repo/test/spark-3.1.2-util-sample:1.1.1" #custom imagePullPolicy: Always mainApplicationFile: local:///app/main.py #custom sparkVersion: "3.1.2" restartPolicy: #type: Never type: OnFailure onFailureRetries: 0 onFailureRetryInterval: 10 onSubmissionFailureRetries: 0 onSubmissionFailureRetryInterval: 20 timeToLiveSeconds: 3600 # 1시간 있다가 sparkapplication 사라지는 설정 sparkConf: "spark.ui.enabled": "false" #ui 안볼거라서 해제 driver: cores: 1 coreLimit: "50m" memory: "512m" labels: version: 3.1.2 serviceAccount: sparkoperator-spark-operator # sa executor: cores: 1 instances: 3 memory: "512m" labels: version: 3.1.2 |
시행착오
1. SKO) role 권한 때문에 Forbidden 에러
serviceaccount, clusterrole, clusterolebinding 잘 몰라서 헤멧어요.
User \\"system:serviceaccount:airflow:airflow-worker\\"
cannot get resource \\"pods/log\\" in API group \\"\\" in the namespace \\"default\\"","reason":"Forbidden"https://mightytedkim.tistory.com/42
Kubernetes) Forbidden 에러, clusterrole과 serviceaccount로 해결
Forbidden 에러, clusterrole과 serviceaccount로 해결 clusterrole과 serviceaccount 확인하기 spark 테스트하는 도중 권한 관련 로그를 접했어요 #kubernetes.client.rest.ApiException: (403) #Reason: Forbi..
mightytedkim.tistory.com
2. SKO) sensor의 task_id 때문에 에러
task_id가 일치하는지 꼭 확인하기
application_name="{{ task_instance.xcom_pull(task_ids='task1-spark')['metadata']['name'] }}",[2021-11-24 00:42:17,311] {taskinstance.py:1115} INFO - Executing <Task(SparkKubernetesSensor): sample-sko-spark-log> on 2021-11-24T00:41:54.293316+00:00 [2021-11-24 00:42:17,315] {standard_task_runner.py:52} INFO - Started process 18 to run task [2021-11-24 00:42:17,320] {standard_task_runner.py:76} INFO - Running: ['airflow', 'tasks', 'run', 'sample-sko-spark', 'sample-sko-spark-log', '2021-11-24T00:41:54.293316+00:00', '--job-id', '1038', '--pool', 'default_pool', '--raw', '--subdir', '/opt/airflow/dags/repo/dags/sample/sample-sko-spark.py', '--cfg-path', '/tmp/tmp03hpz6js', '--error-file', '/tmp/tmpfae_wehi'] [2021-11-24 00:42:17,322] {standard_task_runner.py:77} INFO - Job 1038: Subtask sample-sko-spark-log [2021-11-24 00:42:17,401] {logging_mixin.py:109} INFO - Running <TaskInstance: sample-sko-spark.sample-sko-spark-log 2021-11-24T00:41:54.293316+00:00 [running]> on host sampleskosparksampleskosparklog.26806aa4c99041bb8660935ddce4953 [2021-11-24 00:42:17,498] {taskinstance.py:1463} ERROR - Task failed with exception Traceback (most recent call last): File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/taskinstance.py", line 1165, in _run_raw_task self._prepare_and_execute_task_with_callbacks(context, task) File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/taskinstance.py", line 1246, in _prepare_and_execute_task_with_callbacks self.render_templates(context=context) File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/taskinstance.py", line 1755, in render_templates self.task.render_template_fields(context) File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/baseoperator.py", line 997, in render_template_fields self._do_render_template_fields(self, self.template_fields, context, jinja_env, set()) File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/baseoperator.py", line 1010, in _do_render_template_fields rendered_content = self.render_template(content, context, jinja_env, seen_oids) File "/home/airflow/.local/lib/python3.6/site-packages/airflow/models/baseoperator.py", line 1047, in render_template return jinja_env.from_string(content).render(**context) File "/home/airflow/.local/lib/python3.6/site-packages/jinja2/environment.py", line 1090, in render self.environment.handle_exception() File "/home/airflow/.local/lib/python3.6/site-packages/jinja2/environment.py", line 832, in handle_exception reraise(*rewrite_traceback_stack(source=source)) File "/home/airflow/.local/lib/python3.6/site-packages/jinja2/_compat.py", line 28, in reraise raise value.with_traceback(tb) File "<template>", line 1, in top-level template code File "/home/airflow/.local/lib/python3.6/site-packages/jinja2/sandbox.py", line 384, in getitem return obj[argument] jinja2.exceptions.UndefinedError: 'None' has no attribute 'metadata' |
3. SKO) application_file 읽기 버그
application_file=pathlib.Path("/opt/airflow/dags/repo/script/sample/sample-sko-spark.yaml").read_text()https://github.com/apache/airflow/issues/17371
File contents of application_file are not loaded due to missing open & read functions · Issue #17371 · apache/airflow
Apache Airflow version: 2.0.1 Kubernetes version: 1.20.7 Driver: Docker 20.10.7 Environment: Local minikube Cloud provider or hardware configuration: 2 GHz Quad-Core Intel Core i5 Processor, 16GB R...
github.com
공식 문서
https://airflow.apache.org/docs/apache-airflow-providers-cncf-kubernetes/stable/operators.html
KubernetesPodOperator — apache-airflow-providers-cncf-kubernetes Documentation
airflow.apache.org
GitHub - apache/airflow: Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows - GitHub - apache/airflow: Apache Airflow - A platform to programmatically author, schedule, and monitor work...
github.com
GitHub - apache/airflow: Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows - GitHub - apache/airflow: Apache Airflow - A platform to programmatically author, schedule, and monitor work...
github.com
'Data > Airflow' 카테고리의 다른 글
| udemy)Airflow Operators Guide_1,2장 :: mightytedkim (0) | 2022.01.13 |
|---|---|
| Airflow) helm Api 설정 켜기_auth_backend (0) | 2021.12.17 |
| Airflow) K8S Pod 만들기_k8sPodOperator, helm (5) | 2021.11.12 |
| Airflow) log를 minio에 저장_connection,yaml (0) | 2021.11.12 |
| Airflow) Kubernetes에 올리기(yaml) (0) | 2021.10.28 |