728x90
반응형

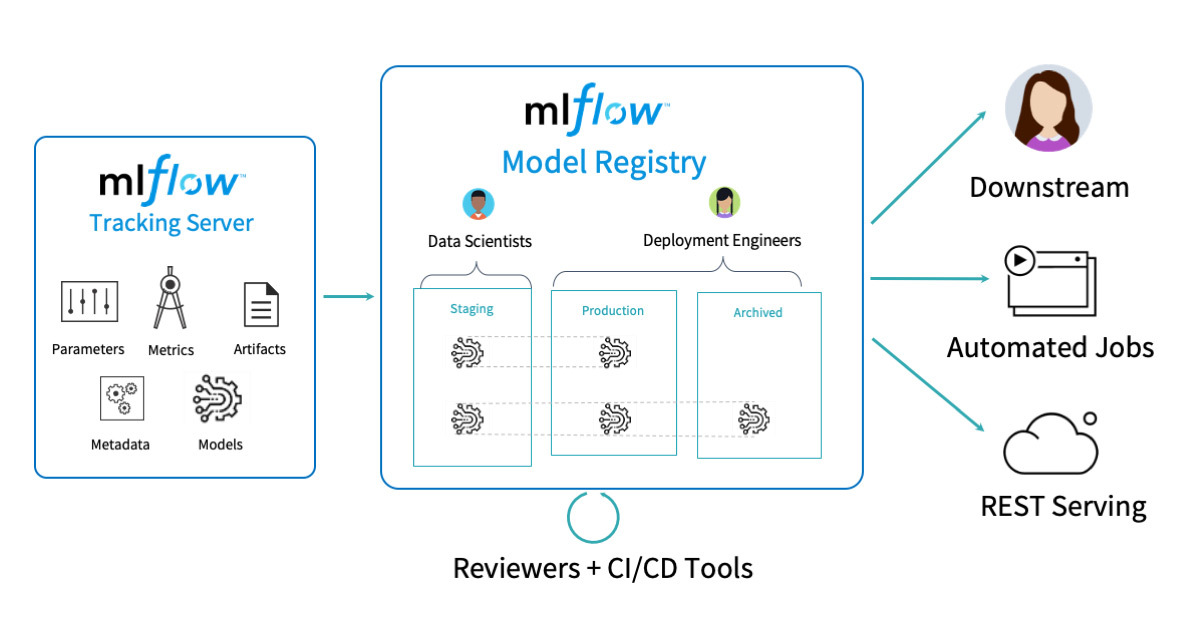
mlflow는 모델을 저장하고 비교하는 플랫폼
서빙까지는 좀 무리가 있는것 같아요
airflow에서 mlflow로 던지는 방법으로 사용하려고 해요
결과
# $k get all -n mlflow
NAME READY STATUS RESTARTS AGE
pod/mlflow-deployment-75686677bf-k4bvx 1/1 Running 4 (51d ago) 59d
pod/mlflow-postgres-0 1/1 Running 1 (51d ago) 59d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/mlflow-postgres-service NodePort 10.98.250.201 <none> 5432:30112/TCP 59d
service/mlflow-service NodePort 10.104.33.19 <none> 5000:30013/TCP 59d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/mlflow-deployment 1/1 1 1 59d
NAME DESIRED CURRENT READY AGE
replicaset.apps/mlflow-deployment-75686677bf 1 1 1 59d
NAME READY AGE
statefulset.apps/mlflow-postgres 1/1 59d
$k get pvc -n mlflow
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mlflow-pvc-mlflow-postgres-0 Bound pvc-7182d621-5a80-46ad-9662-d1a33c57121f 100Mi RWO rook-ceph-block 59d설치
mlflow-pgsql.yaml
mlflow-pvc.yaml
mlflow.yaml
# $ cat mlflow-pgsql.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mlflow-postgres-config
namespace: mlflow
labels:
app: mlflow-postgres
data:
POSTGRES_DB: mlflow_db
POSTGRES_USER: mlflow_user
POSTGRES_PASSWORD: mlflow_pwd
PGDATA: /var/lib/postgresql/mlflow/data
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mlflow-postgres
namespace: mlflow
labels:
app: mlflow-postgres
spec:
selector:
matchLabels:
app: mlflow-postgres
serviceName: "mlflow-postgres-service"
replicas: 1
template:
metadata:
labels:
app: mlflow-postgres
spec:
containers:
- name: mlflow-postgres
image: hgkim/library/postgres:11
ports:
- containerPort: 5432
protocol: TCP
envFrom:
- configMapRef:
name: mlflow-postgres-config
resources:
requests:
memory: "1Gi"
cpu: "500m"
volumeMounts:
- name: mlflow-pvc
mountPath: /var/lib/postgresql/mlflow
volumeClaimTemplates:
- metadata:
name: mlflow-pvc
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: mlflow-postgres-service
namespace: mlflow
labels:
svc: mlflow-postgres-service
spec:
type: NodePort
ports:
- nodePort: 30112
port: 5432
protocol: TCP
targetPort: 5432
selector:
app: mlflow-postgres
$ cat mlflow-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mlflow-pvc-mlflow-postgres-0
namespace: mlflow
labels:
app: mlflow-postgres
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
storageClassName: rook-ceph-block
실행
- 설정
# $ cat requirements.txt
toml
pyarrow
s3fs==2021.11.1
boto3
mlflow
sklearn
$ cat conf/configs.toml
[app.mlflow]
object_storage_endpoint = 'http://10.***.35.32:30071'
object_storage_bucket = "***"
object_storage_key = "model/1.raw_data/train.csv"
mlflow_tracking_url = "http://10.***.35.32:30013"
#mlflow
alpha = 0.1
l1_ratio = 0.1
artifact_path = '***-model-wine'
registered_model_name = '***-model-wine'
- jupyterhub나 airflow에서 실행
# $ cat main.py
# Impor/ting in necessary libraries
import os
import numpy as np
import pandas as pd
import logging.config
import toml
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
import io
import pyarrow.parquet as pq
import s3fs
import argparse
configs = toml.load("./conf/configs.toml")
app_configs = configs["app"]
print(app_configs)
class MlflowOperations:
def __init__(self, conf):
print("==init==")
self.conf = conf
self.alpha = self.conf["alpha"]
self.l1_ratio = self.conf["l1_ratio"]
#for Logging model to MLFlo
os.environ['MLFLOW_S3_ENDPOINT_URL'] = self.conf["object_storage_endpoint"]
os.environ['AWS_ACCESS_KEY_ID'] = 'access-key'
os.environ['AWS_SECRET_ACCESS_KEY'] = 'secret-key'
def open_mlflow_session(self):
print("==open_mlflow_session==")
mlflow.set_tracking_uri(self.conf["mlflow_tracking_url"])
mlflow.set_experiment("***-wine-test")
return mlflow
def load(self):
print("==load==")
object_storage_fs = s3fs.S3FileSystem(
anon=False,
use_ssl=False,
client_kwargs={
"region_name": "",
"endpoint_url": self.conf['object_storage_endpoint'], #'http://10.233.21.208:80',
"aws_access_key_id": 'access-key',
"aws_secret_access_key": 'secret-key',
"verify": False,
}
)
return pd.read_csv(object_storage_fs.open('{}/{}'.format( self.conf['object_storage_bucket'], self.conf['object_storage_key']),mode='rb'))
def split_data(self):
print("==split_data==")
# Loading data from a CSV file
df_wine = self.load()
print(df_wine)
# # Separating the target class ('quality') from remainder of the training data
X = df_wine.drop(columns = ['quality','kind'])
y = df_wine[['quality']]
# Splitting the data into training and validation sets
X_train, self.X_val, y_train, self.y_val = train_test_split(X, y, random_state = 30)
self.X_train = np.float32(X_train)
self.y_train = np.float32(y_train)
self.X_train = np.nan_to_num(X_train, nan=-9999, posinf=33333333, neginf=33333333)
self.y_train = np.nan_to_num(y_train, nan=-9999, posinf=33333333, neginf=33333333)
def train_data(self):
mlfow = self.open_mlflow_session()
# Running MLFlow script
with mlflow.start_run():
# Instantiating model with model parameters
model = ElasticNet(alpha = self.alpha, l1_ratio = self.l1_ratio)
# Fitting training data to the model
model.fit(self.X_train, self.y_train)
# Running prediction on validation dataset
preds = model.predict(self.X_val)
# Getting metrics on the validation dataset
rmse = mean_squared_error(preds, self.y_val)
abs_error = mean_absolute_error(preds, self.y_val)
r2 = r2_score(preds, self.y_val)
# Logging params and metrics to MLFlow
mlflow.log_param('alpha', self.alpha)
mlflow.log_param('l1_ratio', self.l1_ratio)
mlflow.log_metric('rmse', rmse)
mlflow.log_metric('abs_error', abs_error)
mlflow.log_metric('r2', r2)
# Logging training data
#mlflow.log_artifact(local_path = './train.csv')
# Logging training code
#mlflow.log_artifact(local_path = './main.py')
# Logging model to MLFlow
mlflow.sklearn.log_model(sk_model = model,
artifact_path = self.conf["artifact_path"],
registered_model_name = self.conf["registered_model_name"] )
def main(conf):
print("==main==")
# argparse
parser = argparse.ArgumentParser(description='Argparse')
parser.add_argument('--alpha', type=float, default=0.1)
parser.add_argument('--l1ratio', type=float, default=0.1)
args = parser.parse_args()
# argument check
if args.alpha != 0.1:
conf["mlflow"]["alpha"] = args.alpha
if args.l1ratio != 0.1:
conf["mlflow"]["l1_ratio"] = args.l1ratio
print("------")
print("alpha: " + str(conf["mlflow"]["alpha"]))
print("l1ratio: " + str(conf["mlflow"]["l1_ratio"]))
print("------")
session = MlflowOperations(conf["mlflow"])
session.split_data()
session.train_data()
if __name__ == "__main__":
main(configs["app"])
728x90
반응형
'AI > MLOps' 카테고리의 다른 글
| 데이터 잡부의 MLOps도전기 (3) - 모델 배포를 위해 FaaS를 도입해보자 #Nuclio (1) | 2024.03.31 |
|---|---|
| 데이터 잡부의 MLOps도전기 (2) - 라벨링 툴로 CVAT을 선택한 이유 #VISION (0) | 2024.01.21 |
| 데이터 잡부의 MLOps도전기 (1) #이미지 불량탐지 (6) | 2024.01.07 |
| Bentoml) Yatai 1.0 에서 무엇이 바뀌었을까 (0) | 2022.10.10 |
| Mlflow) python, airflow로 테스트해보기 (0) | 2022.06.26 |